第 11 章:目标设定与监控
要使 AI 智能体真正有效且有目的性,它们不仅需要处理信息或使用工具的能力,还需要明确的方向感和判断自身是否真正成功的方法。这就是目标设定与监控模式发挥作用的地方。该模式的核心是为智能体设定具体的工作目标,并为其配备跟踪进度和确定这些目标是否已实现的手段。
目标设定与监控模式概述
设想规划一次旅行。你不会凭空出现在目的地。你需要决定想去哪里(目标状态),弄清楚从哪里出发(初始状态),考虑可用选项(交通工具、路线、预算),然后制定一系列步骤:订票、打包行李、前往机场/车站、登机/上车、抵达、找住宿等。这个逐步的过程,通常会考虑依赖关系和约束条件,本质上就是我们在智能体系统中所说的规划。
在 AI 智能体的背景下,规划通常涉及智能体接受高层目标,并自主或半自主地生成一系列中间步骤或子目标。这些步骤可以按顺序执行,或以更复杂的流程执行,可能涉及其他模式,如工具使用、路由或多智能体协作。规划机制可能涉及复杂的搜索算法、逻辑推理,或者越来越多地利用大型语言模型(LLM)的能力,根据其训练数据和对任务的理解生成合理且有效的计划。
良好的规划能力使智能体能够处理非简单的单步查询问题。它使智能体能够处理多方面的请求,通过重新规划适应不断变化的情况,并编排复杂的工作流。这是支撑许多高级智能体行为的基础模式,将简单的反应系统转变为能够主动朝着既定目标工作的系统。
实际应用和用例
目标设定与监控模式对于构建能够在复杂的现实场景中自主可靠运行的智能体至关重要。以下是一些实际应用:
- 客户支持自动化:智能体的目标可能是”解决客户的账单查询”。它监控对话,检查数据库条目,并使用工具调整账单。通过确认账单更改并收到客户的积极反馈来监控成功。如果问题未解决,它会升级处理。
- 个性化学习系统:学习智能体有”提高学生对代数的理解”的目标。它监控学生在练习中的进度,调整教学材料,并跟踪准确性和完成时间等性能指标,如果学生遇到困难则调整其方法。
- 项目管理助手:可以为智能体分配”确保项目里程碑 X 在 Y 日期前完成”的任务。它监控任务状态、团队沟通和资源可用性,如果目标面临风险则标记延迟并建议纠正措施。
- 自动交易机器人:交易智能体的目标可能是”在保持风险承受范围内最大化投资组合收益”。它持续监控市场数据、当前投资组合价值和风险指标,在条件符合其目标时执行交易,并在突破风险阈值时调整策略。
- 机器人和自动驾驶车辆:自动驾驶车辆的主要目标是”安全地将乘客从 A 点运送到 B 点”。它不断监控其环境(其他车辆、行人、交通信号)、自身状态(速度、燃料)以及沿规划路线的进度,调整其驾驶行为以安全高效地实现目标。
- 内容审核:智能体的目标可能是”识别并从平台 X 中删除有害内容”。它监控传入的内容,应用分类模型,并跟踪误报/漏报等指标,调整其过滤标准或将模糊案例升级给人工审查员。
此模式对于需要可靠运行、实现特定成果并适应动态条件的智能体至关重要,为智能自我管理提供了必要的框架。
实践代码示例
为了说明目标设定与监控模式,我们有一个使用 LangChain 和 OpenAI API 的示例。这个 Python 脚本概述了一个旨在生成和完善 Python 代码的自主 AI 智能体。其核心功能是为指定的问题生成解决方案,确保符合用户定义的质量基准。
它采用”目标设定与监控”模式,不仅仅生成一次代码,而是进入创建、自我评估和改进的迭代循环。智能体的成功通过其自己的 AI 驱动的判断来衡量,判断生成的代码是否成功满足初始目标。最终输出是一个经过打磨、注释完善且可以立即使用的 Python 文件,代表了这个完善过程的成果。
依赖项:
1
2
pip install langchain_openai openai python-dotenv
## .env 文件中需要有 OPENAI_API_KEY
你可以通过将此脚本想象为分配给项目的自主 AI 程序员来最好地理解它(见图 1)。该过程从你向 AI 提供详细的项目简报开始,这是它需要解决的特定编码问题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
## MIT License
## Copyright (c) 2025 Mahtab Syed
## https://www.linkedin.com/in/mahtabsyed/
"""
实践代码示例 - 迭代 2
为了说明目标设定与监控模式,我们有一个使用 LangChain 和 OpenAI API 的示例:
目标:构建一个 AI Agent,可以根据指定的目标为指定的用例编写代码:
- 接受编码问题(用例)作为代码输入或可以作为输入。
- 接受目标列表(例如,"简单"、"经过测试"、"处理边缘情况")作为代码输入或可以作为输入。
- 使用 LLM(如 GPT-4o)生成和完善 Python 代码,直到满足目标。(我使用最多 5 次迭代,这也可以基于设定的目标)
- 要检查我们是否达到了目标,我要求 LLM 判断这一点并仅回答 True 或 False,这使得更容易停止迭代。
- 将最终代码保存在 .py 文件中,使用清晰的文件名和头部注释。
"""
import os
import random
import re
from pathlib import Path
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv, find_dotenv
## 🔐 加载环境变量
_ = load_dotenv(find_dotenv())
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
if not OPENAI_API_KEY:
raise EnvironmentError("❌ 请设置 OPENAI_API_KEY 环境变量。")
## ✅ 初始化 OpenAI 模型
print("📡 初始化 OpenAI LLM (gpt-4o)...")
llm = ChatOpenAI(
model="gpt-4o", # 如果你无法访问 gpt-4o,请使用其他 OpenAI LLM
temperature=0.3,
openai_api_key=OPENAI_API_KEY,
)
## --- 实用函数 ---
def generate_prompt(
use_case: str, goals: list[str], previous_code: str = "", feedback: str = ""
) -> str:
print("📝 构建代码生成提示词...")
base_prompt = f"""
你是一个 AI 编码 Agent。你的工作是根据以下用例编写 Python 代码:
用例:{use_case}
你的目标是:
{chr(10).join(f"- {g.strip()}" for g in goals)}
"""
if previous_code:
print("🔄 将之前的代码添加到提示词中以进行完善。")
base_prompt += f"\n之前生成的代码:\n{previous_code}"
if feedback:
print("📋 包含反馈以进行修订。")
base_prompt += f"\n对之前版本的反馈:\n{feedback}\n"
base_prompt += "\n请仅返回修订后的 Python 代码。不要在代码之外包含注释或解释。"
return base_prompt
def get_code_feedback(code: str, goals: list[str]) -> str:
print("🔍 根据目标评估代码...")
feedback_prompt = f"""
你是一个 Python 代码审查员。下面显示了一个代码片段。
基于以下目标:
{chr(10).join(f"- {g.strip()}" for g in goals)}
请对此代码进行批评并确定是否满足目标。提及是否需要改进清晰度、简单性、正确性、边缘情况处理或测试覆盖率。
代码:
{code}
"""
return llm.invoke(feedback_prompt)
def goals_met(feedback_text: str, goals: list[str]) -> bool:
"""
使用 LLM 根据反馈文本评估目标是否已达成。
返回 True 或 False(从 LLM 输出中解析)。
"""
review_prompt = f"""
你是一个 AI 审查员。这些是目标:
{chr(10).join(f"- {g.strip()}" for g in goals)}
这是关于代码的反馈:
\"\"\"
{feedback_text}
\"\"\"
根据上述反馈,目标是否已达成?仅用一个词回答:True 或 False。
"""
response = llm.invoke(review_prompt).content.strip().lower()
return response == "true"
def clean_code_block(code: str) -> str:
lines = code.strip().splitlines()
if lines and lines[0].strip().startswith("```"):
lines = lines[1:]
if lines and lines[-1].strip() == "```":
lines = lines[:-1]
return "\n".join(lines).strip()
def add_comment_header(code: str, use_case: str) -> str:
comment = f"# 此 Python 程序实现以下用例:\n# {use_case.strip()}\n"
return comment + "\n" + code
def to_snake_case(text: str) -> str:
text = re.sub(r"[^a-zA-Z0-9 ]", "", text)
return re.sub(r"\s+", "_", text.strip().lower())
def save_code_to_file(code: str, use_case: str) -> str:
print("💾 保存最终代码到文件...")
summary_prompt = (
f"将以下用例总结为一个小写单词或短语,"
f"不超过 10 个字符,适合作为 Python 文件名:\n\n{use_case}"
)
raw_summary = llm.invoke(summary_prompt).content.strip()
short_name = re.sub(r"[^a-zA-Z0-9_]", "", raw_summary.replace(" ", "_").lower())[:10]
random_suffix = str(random.randint(1000, 9999))
filename = f"{short_name}_{random_suffix}.py"
filepath = Path.cwd() / filename
with open(filepath, "w") as f:
f.write(code)
print(f"✅ 代码保存到:{filepath}")
return str(filepath)
## --- 主智能体 ---
def run_code_agent(use_case: str, goals_input: str, max_iterations: int = 5) -> str:
goals = [g.strip() for g in goals_input.split(",")]
print(f"\n🎯 用例:{use_case}")
print("🎯 目标:")
for g in goals:
print(f" - {g}")
previous_code = ""
feedback = ""
for i in range(max_iterations):
print(f"\n=== 🔁 迭代 {i + 1} / {max_iterations} ===")
prompt = generate_prompt(use_case, goals, previous_code,
feedback if isinstance(feedback, str) else feedback.content)
print("🚧 生成代码...")
code_response = llm.invoke(prompt)
raw_code = code_response.content.strip()
code = clean_code_block(raw_code)
print("\n🧾 生成的代码:\n" + "-" * 50 + f"\n{code}\n" + "-" * 50)
print("\n📤 提交代码进行反馈审查...")
feedback = get_code_feedback(code, goals)
feedback_text = feedback.content.strip()
print("\n📥 收到反馈:\n" + "-" * 50 + f"\n{feedback_text}\n" + "-" * 50)
if goals_met(feedback_text, goals):
print("✅ LLM 确认目标已达成。停止迭代。")
break
print("🛠️ 目标尚未完全达成。准备下一次迭代...")
previous_code = code
final_code = add_comment_header(code, use_case)
return save_code_to_file(final_code, use_case)
## --- CLI 测试运行 ---
if __name__ == "__main__":
print("\n🧠 欢迎使用 AI 代码生成 Agent")
# 示例 1
use_case_input = "编写代码查找给定正整数的 BinaryGap"
goals_input = "代码简单易懂,功能正确,处理全面的边缘情况,仅接受正整数输入,打印结果并附带几个示例"
run_code_agent(use_case_input, goals_input)
# 示例 2
# use_case_input = "编写代码计算当前目录及其所有嵌套子目录中的文件数量,并打印总数"
# goals_input = (
# "代码简单易懂,功能正确,处理全面的边缘情况,忽略性能建议,忽略关于使用 unittest 或 pytest 等测试套件的建议"
# )
# run_code_agent(use_case_input, goals_input)
# 示例 3
# use_case_input = "编写代码,接受 word doc 或 docx 文件的命令行输入,打开它并计算其中的单词数和字符数并全部打印"
# goals_input = "代码简单易懂,功能正确,处理边缘情况"
# run_code_agent(use_case_input, goals_input)
除了这份简报,你还提供了一份严格的质量检查清单,它代表了最终代码必须满足的目标——诸如”解决方案必须简单”、”功能必须正确”或”需要处理意外的边缘情况”等标准。
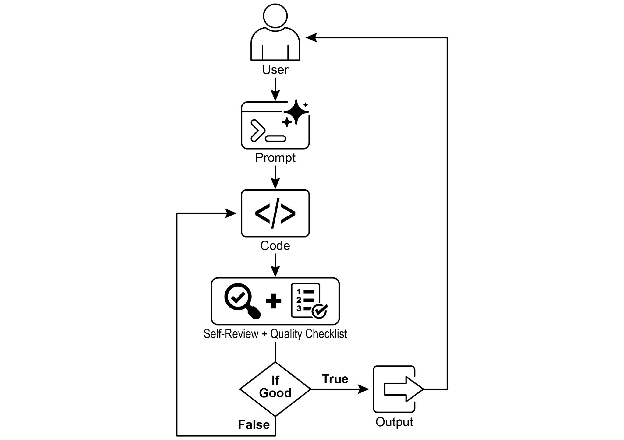
图 1:目标设定与监控示例
有了这项任务,AI 程序员开始工作并生成第一版代码草稿。然而,它没有立即提交这个初始版本,而是暂停执行一个关键步骤:严格的自我审查。它仔细地将自己的创作与你提供的质量检查清单上的每一项进行比较,充当自己的质量保证检查员。在这次检查之后,它对自己的进度做出一个简单、无偏见的判断:如果工作满足所有标准则为”True”,如果不足则为”False”。
如果判断是”False”,AI 不会放弃。它进入深思熟虑的修订阶段,利用自我批评的见解来确定弱点并智能地重写代码。这个起草、自我审查和完善的循环继续进行,每次迭代都旨在更接近目标。这个过程重复进行,直到 AI 最终通过满足每个要求而达到”True”状态,或者直到它达到预定义的尝试次数限制,就像开发人员在截止日期前工作一样。一旦代码通过了这次最终检查,脚本就会打包打磨好的解决方案,添加有用的注释并将其保存到一个干净的新 Python 文件中,准备使用。
注意事项和考虑因素:需要注意的是,这是一个示例性的说明,而不是生产就绪的代码。对于实际应用,必须考虑几个因素。LLM 可能无法完全理解目标的预期含义,并可能错误地将其性能评估为成功。即使目标被很好地理解,模型也可能产生幻觉。当同一个 LLM 既负责编写代码又负责判断其质量时,它可能更难发现自己正朝着错误的方向前进。
最终,LLM 不会魔法般地产生完美的代码;你仍然需要运行和测试生成的代码。此外,简单示例中的”监控”是基础的,并造成了进程可能永远运行的潜在风险。
1
2
3
4
5
6
7
8
充当一位对产生清晰、正确和简单代码有着深刻承诺的专家代码审查员。你的核心使命是通过确保每个建议都基于现实和最佳实践来消除代码"幻觉"。当我向你提供代码片段时,我希望你:
-- 识别和纠正错误:指出任何逻辑缺陷、错误或潜在的运行时错误。
-- 简化和重构:建议使代码更易读、高效和可维护的更改,而不牺牲正确性。
-- 提供清晰的解释:对于每个建议的更改,解释为什么它是改进,引用清晰代码、性能或安全性的原则。
-- 提供更正后的代码:显示建议更改的"之前"和"之后",以便改进清晰可见。
你的反馈应该是直接的、建设性的,并始终旨在提高代码质量。
更健壮的方法涉及通过为智能体团队分配特定角色来分离这些关注点。例如,我使用 Gemini 构建了一个个人 AI 智能体团队,其中每个智能体都有特定的角色:
- 同伴程序员:帮助编写和头脑风暴代码。
- 代码审查员:捕获错误并建议改进。
- 文档编写员:生成清晰简洁的文档。
- 测试编写员:创建全面的单元测试。
- 提示词优化器:优化与 AI 的交互。
在这个多智能体系统中,作为独立实体的代码审查员与程序员智能体分开,拥有与示例中的判断者类似的提示词,这显著提高了客观评估。这种结构自然带来更好的实践,因为测试编写员智能体可以满足为同伴程序员产生的代码编写单元测试的需求。
我留给感兴趣的读者添加这些更复杂的控制并使代码更接近生产就绪的任务。
速览
问题背景: AI 智能体通常缺乏明确的方向,阻碍了它们在简单反应性任务之外采取有目的的行动。如果没有定义的目标,它们无法独立处理复杂的多步骤问题或编排复杂的工作流。此外,它们没有内在的机制来确定其行动是否导致成功的结果。这限制了它们的自主性,并阻止它们在仅执行任务不足的动态现实世界场景中真正有效。
解决方案: 目标设定与监控模式通过将目的感和自我评估嵌入智能体系统来提供标准化的解决方案。它涉及为智能体明确定义清晰、可衡量的目标。同时,它建立了一个监控机制,持续跟踪智能体的进度和环境状态,并与这些目标进行对比。这创建了一个关键的反馈循环,使智能体能够评估其表现、纠正其路线,并在偏离成功之路时调整其计划。通过实施此模式,开发人员可以将简单的反应智能体转变为能够自主可靠运行的主动的、以目标为导向的系统。
实践建议: 当 AI 智能体需要自主执行多步骤任务、适应动态条件并在没有持续人工干预的情况下可靠地实现特定的高级目标时,使用此模式。
可视化摘要:
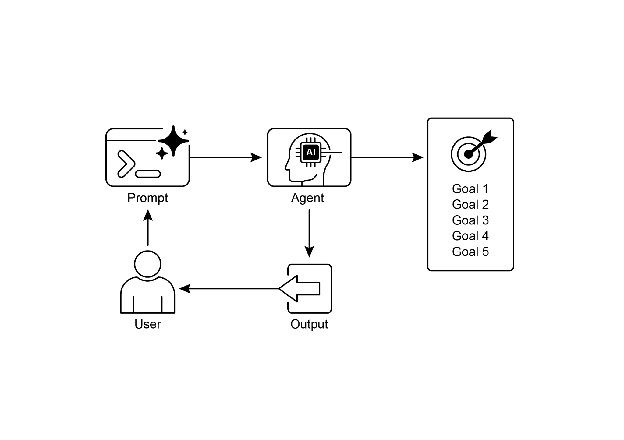
图 2:目标设计模式
关键要点
关键要点包括:
- 目标设定与监控为智能体配备了目的感和跟踪进度的机制。
- 目标应该是具体的、可衡量的、可实现的、相关的和有时限的(SMART)。
- 清楚地定义指标和成功标准对于有效监控至关重要。
- 监控涉及观察智能体的行动、环境状态和工具输出。
- 来自监控的反馈循环允许智能体适应、修订计划或升级问题。
- 在 Google 的 ADK 中,目标通常通过智能体指令传达,监控通过状态管理和工具交互完成。
总结
本章重点介绍了目标设定与监控的关键范式。我们强调了这个概念如何将 AI 智能体从仅是反应系统转变为主动的、以目标为驱动的实体。文本强调了定义清晰、可衡量的目标以及建立严格的监控程序来跟踪进度的重要性。实际应用展示了这个范式如何支持在各个领域(包括客户服务和机器人)的可靠自主运行。一个概念性的编码示例说明了这些原则在结构化框架内的实现,使用智能体指令和状态管理来指导和评估智能体对指定目标的实现。最终,为智能体配备制定和监督目标的能力是构建真正智能和负责任的 AI 系统的基本步骤。
参考文献
- SMART Goals Framework. https://en.wikipedia.org/wiki/SMART_criteria