第 8 章:记忆管理
有效的记忆管理对于智能体管理信息至关重要。与人类类似,智能体需要不同类型的记忆才能高效运行。本章深入探讨记忆管理,重点关注智能体的短期记忆和持久(长期)记忆需求。
在智能体中,记忆指智能体利用过去交互、观察和学习经验的能力。这种能力帮助智能体做出决策、维护对话上下文并持续改进。智能体记忆通常分为两大主要类型:
- 短期记忆(上下文记忆): 类似于工作记忆,保存当前正在处理或最近访问的信息。对于使用大语言模型(LLM)的智能体,短期记忆主要存在于上下文窗口中。该窗口包含最近消息、智能体回复、工具使用结果以及当前交互中的智能体反思和其他相关信息,所有这些都为 LLM 的后续响应和操作提供信息支撑。上下文窗口容量有限,制约了智能体可访问的近期信息量。高效的短期记忆管理需要在有限空间内保留最相关信息,可能通过总结旧对话片段或突出关键细节等技术实现。具有”长上下文”窗口的模型只是扩展了短期记忆容量,允许单次交互保存更多信息。然而,这种上下文仍是临时的,会话结束即丢失,且每次处理可能成本高昂。因此,智能体需要独立的记忆类型来实现真正的持久性、调用过往信息并建立持久知识库。
- 长期记忆(持久记忆): 作为智能体在交互、任务或更长时间内所需信息的存储库,类似于长期知识库。数据通常存储在智能体环境之外,常见于数据库、知识图谱或向量数据库中。在向量数据库中,信息被转换为数字向量存储,使智能体能通过相似性(而非精确关键字匹配)检索数据,这个过程称为语义搜索。当智能体需要长期记忆时,会查询外部存储、检索相关数据并集成到短期上下文中供即时使用,从而将先前知识与当前交互结合起来。
实际应用与用例
记忆管理对于智能体保留信息并随时间智能执行至关重要。这是智能体具备问答能力的必要条件。主要应用包括:
- 聊天机器人与对话式 AI: 维护对话流程依赖短期记忆。聊天机器人需要记住先前用户输入以提供连贯响应。长期记忆使聊天机器人能回忆用户偏好、过往问题或先前讨论,提供个性化和持续的交互体验
- 面向任务的智能体: 管理多步骤任务的智能体使用短期记忆跟踪先前步骤、当前进度和总体目标。此类信息可能驻留在任务上下文或临时存储中。长期记忆对于访问不在即时上下文中的特定用户相关数据至关重要
- 个性化体验: 提供定制交互的智能体使用长期记忆存储和检索用户偏好、过往行为和个人信息。这使智能体能够提供个性化响应和建议
- 学习与改进:智能体通过从过去交互中学习来提升性能。成功策略、错误和新信息存储于长期记忆中,促进未来适应。强化学习智能体可以存储学习策略或知识
- 信息检索(RAG): 设计用于回答问题的智能体访问知识库(即其长期记忆),通常在检索增强生成(RAG)中实现。智能体检索相关文档或数据以指导其响应
- 自主系统: 机器人或自动驾驶汽车需要记忆来存储地图、路线、对象位置和学习行为。这涉及用于即时环境的短期记忆和用于通用环境知识的长期记忆
记忆使智能体维护历史、持续学习、个性化交互并管理复杂的时间依赖问题。
实操代码:Google ADK 中的记忆管理
Google 智能体开发工具包(ADK)提供了结构化的上下文和记忆管理方法,包含实际应用组件。深入理解 ADK 的 Session、State 和 Memory 对构建需保留信息的智能体至关重要。
与人类交互类似,智能体需要能够回忆先前交流以进行连贯对话。ADK 通过三个核心概念简化了上下文管理:
每次与智能体的交互可视为独特的对话线程,智能体可能需要访问早期数据。ADK 将其结构化如下:
- Session(会话): 独立的聊天线程,记录该特定交互的消息和操作(Events),同时存储与该对话相关的临时数据(State)
- State(状态)(session.state): 存储在 Session 中的数据,包含仅与当前活动聊天线程相关的信息
- Memory(记忆): 来自各种过往聊天或外部来源信息的可搜索存储库,作为超出即时对话范围的数据检索资源
ADK 为构建复杂、有状态和上下文感知的智能体提供专用服务:SessionService 管理聊天线程(启动、记录和终止 Session 对象),MemoryService 监督长期知识(Memory)的存储和检索。
SessionService 和 MemoryService 均提供多种配置选项,允许根据应用需求选择存储方法。内存选项适用于测试目的(数据不持久),持久存储和可扩展需求则支持数据库和云服务。
Session:跟踪每次聊天
ADK 中的 Session 对象旨在跟踪和管理单个聊天线程。在与智能体对话时,SessionService 会生成一个 Session 对象,表示为 google.adk.sessions.Session。此对象封装了与特定对话线程相关的所有数据,包括唯一标识符(id、app_name、user_id)、作为 Event 对象的事件的时间顺序记录、用于会话特定临时数据的存储区域(称为 state)以及指示最后更新的时间戳(last_update_time)。开发人员通常通过 SessionService 间接与 Session 对象交互。SessionService 负责管理对话会话的生命周期,包括启动新会话、恢复先前的会话、记录会话活动(包括状态更新)、识别活动会话以及管理会话数据的删除。ADK 提供几种具有不同存储机制的 SessionService 实现,用于会话历史和临时数据,例如 InMemorySessionService,适合测试但不提供跨应用程序重启的数据持久性。
1
2
3
4
5
## 示例:使用 InMemorySessionService
## 这适用于不需要跨应用程序重启的数据持久性的本地开发和测试。
from google.adk.sessions import InMemorySessionService
session_service = InMemorySessionService()
然后是 DatabaseSessionService,如果您想可靠地保存到您管理的数据库。
1
2
3
4
5
6
7
8
9
## 示例:使用 DatabaseSessionService
## 这适用于需要持久存储的生产或开发。
## 您需要配置数据库 URL(例如,用于 SQLite、PostgreSQL 等)。
## 需要:pip install google-adk[sqlalchemy] 和数据库驱动程序(例如,PostgreSQL 的 psycopg2)
from google.adk.sessions import DatabaseSessionService
## 示例使用本地 SQLite 文件:
db_url = "sqlite:///./my_agent_data.db"
session_service = DatabaseSessionService(db_url=db_url)
此外,还有 VertexAiSessionService,它使用 Vertex AI 基础设施在 Google Cloud 上进行可扩展的生产。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
## 示例:使用 VertexAiSessionService
## 这适用于 Google Cloud Platform 上的可扩展生产,利用
## Vertex AI 基础设施进行会话管理。
## 需要:pip install google-adk[vertexai] 和 GCP 设置/身份验证
from google.adk.sessions import VertexAiSessionService
PROJECT_ID = "your-gcp-project-id" # 替换为您的 GCP 项目 ID
LOCATION = "us-central1" # 替换为您想要的 GCP 位置
## 与此服务一起使用的 app_name 应对应于 Reasoning Engine ID 或名称
REASONING_ENGINE_APP_NAME = "projects/your-gcp-project-id/locations/us-central1/reasoningEngines/your-engine-id" # 替换为您的 Reasoning Engine 资源名称
session_service = VertexAiSessionService(project=PROJECT_ID, location=LOCATION)
## 使用此服务时,将 REASONING_ENGINE_APP_NAME 传递给服务方法:
## session_service.create_session(app_name=REASONING_ENGINE_APP_NAME, ...)
## session_service.get_session(app_name=REASONING_ENGINE_APP_NAME, ...)
## session_service.append_event(session, event, app_name=REASONING_ENGINE_APP_NAME)
## session_service.delete_session(app_name=REASONING_ENGINE_APP_NAME, ...)
选择适当的 SessionService 至关重要,因为它决定了智能体交互历史和临时数据的存储方式及其持久性。
每次消息交换都涉及一个循环过程:接收消息,Runner 使用 SessionService 检索或建立 Session,Agent 使用 Session 的上下文(状态和历史交互)处理消息,Agent 生成响应并可能更新状态,Runner 将其封装为 Event,session_service.append_event 方法记录新事件并更新存储中的状态。然后 Session 等待下一条消息。理想情况下,当交互结束时使用 delete_session 方法终止会话。此过程说明了 SessionService 如何通过管理特定于 Session 的历史和临时数据来维护连续性。
State:Session 的草稿本
在 ADK 中,每个代表聊天线程的 Session 都包含 state 组件,类似于智能体在特定对话期间的临时工作记忆。虽然 session.events 记录整个聊天历史,但 session.state 存储和更新与活动聊天相关的动态数据点
从根本上讲,session.state 作为字典运行,以键值对形式存储数据。其核心功能是使智能体保留和管理对连贯对话至关重要的详细信息,如用户偏好、任务进度、增量数据收集或影响后续智能体行为的事件标志
状态结构包含字符串键与可序列化 Python 类型值的配对,包括字符串、数字、布尔值、列表及包含这些基本类型的字典。State 是动态的,在整个对话过程中不断演变。这些更改的持久性取决于配置的 SessionService
可使用键前缀定义数据范围和持久性来组织状态:
- user: 前缀将数据与跨所有会话的用户 ID 关联
- app: 前缀指定应用程序所有用户间共享的数据
- temp: 前缀指示仅对当前处理轮次有效且不持久存储的数据
Agent 通过单个 session.state 字典访问所有状态数据。SessionService 处理数据检索、合并和持久性。应在通过 session_service.append_event() 向会话历史添加 Event 时更新状态。这确保了准确跟踪、在持久服务中的正确保存以及状态更改的安全处理
- 简单方法:使用 output_key(用于智能体回复): 如果您只想将智能体的文本响应直接保存到状态中,这是最简单的方法。设置 LlmAgent 时,只需告诉它要使用的 output_key。Runner 看到这一点并在追加事件时自动创建必要的操作以将响应保存到状态。让我们看一个通过 output_key 演示状态更新的代码示例。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
## 从 Google 智能体开发工具包 (ADK) 导入必要的类
from google.adk.agents import LlmAgent
from google.adk.sessions import InMemorySessionService, Session
from google.adk.runners import Runner
from google.genai.types import Content, Part
## 定义带有 output_key 的 LlmAgent。
greeting_agent = LlmAgent(
name="Greeter",
model="gemini-2.0-flash",
instruction="生成一个简短、友好的问候语。",
output_key="last_greeting"
)
## --- 设置 Runner 和 Session ---
app_name, user_id, session_id = "state_app", "user1", "session1"
session_service = InMemorySessionService()
runner = Runner(
agent=greeting_agent,
app_name=app_name,
session_service=session_service
)
session = session_service.create_session(
app_name=app_name,
user_id=user_id,
session_id=session_id
)
print(f"初始状态:{session.state}")
## --- 运行智能体 ---
user_message = Content(parts=[Part(text="你好")])
print("\n--- 运行 agent ---")
for event in runner.run(
user_id=user_id,
session_id=session_id,
new_message=user_message
):
if event.is_final_response():
print("Agent 已响应。")
## --- 检查更新的状态 ---
## 在 runner 完成处理所有事件*之后*正确检查状态。
updated_session = session_service.get_session(app_name, user_id, session_id)
print(f"\nAgent 运行后的状态:{updated_session.state}")
在幕后,Runner 看到您的 output_key,并在调用 append_event 时自动创建具有 state_delta 的必要操作。
- 标准方法:使用 EventActions.state_delta(用于更复杂的更新): 对于需要执行更复杂操作的时候——例如一次更新多个键、保存不只是文本的内容、针对特定范围(如 user: 或 app:)或进行与智能体文本回复无关的更新——您将手动构建状态更改的字典(state_delta)并将其包含在要追加的 Event 的 EventActions 中。让我们看一个例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
import time
from google.adk.tools.tool_context import ToolContext
from google.adk.sessions import InMemorySessionService
## --- 定义推荐的基于工具的方法 ---
def log_user_login(tool_context: ToolContext) -> dict:
"""
在用户登录事件时更新会话状态。
此工具封装了与用户登录相关的所有状态更改。
参数:
tool_context:由 ADK 自动提供,提供对会话状态的访问。
返回:
确认操作成功的字典。
"""
# 通过提供的上下文直接访问状态。
state = tool_context.state
# 获取当前值或默认值,然后更新状态。
# 这更加清晰并将逻辑共置。
login_count = state.get("user:login_count", 0) + 1
state["user:login_count"] = login_count
state["task_status"] = "active"
state["user:last_login_ts"] = time.time()
state["temp:validation_needed"] = True
print("从 `log_user_login` 工具内部更新了状态。")
return {
"status": "success",
"message": f"已跟踪用户登录。总登录次数:{login_count}。"
}
## --- 使用演示 ---
## 在真实应用程序中,LLM智能体将调用此工具。
## 在这里,我们模拟直接调用以进行演示。
## 1. 设置
session_service = InMemorySessionService()
app_name, user_id, session_id = "state_app_tool", "user3", "session3"
session = session_service.create_session(
app_name=app_name,
user_id=user_id,
session_id=session_id,
state={"user:login_count": 0, "task_status": "idle"}
)
print(f"初始状态:{session.state}")
## 2. 模拟工具调用(在真实应用中,ADK Runner 会执行此操作)
## 我们仅为此独立示例手动创建 ToolContext。
from google.adk.tools.tool_context import InvocationContext
mock_context = ToolContext(
invocation_context=InvocationContext(
app_name=app_name, user_id=user_id, session_id=session_id,
session=session, session_service=session_service
)
)
## 3. 执行工具
log_user_login(mock_context)
## 4. 检查更新的状态
updated_session = session_service.get_session(app_name, user_id, session_id)
print(f"工具执行后的状态:{updated_session.state}")
## 预期输出将显示与"之前"情况相同的状态更改,
## 但代码组织明显更清晰
## 且更健壮。
此代码演示了一种基于工具的方法来管理应用程序中的用户会话状态。它定义了一个函数 log_user_login,充当工具。此工具负责在用户登录时更新会话状态。 该函数接受由 ADK 提供的 ToolContext 对象,以访问和修改会话的状态字典。在工具内部,它递增 user:login_count,将 task_status 设置为”active”,记录 user:last_login_ts(时间戳),并添加临时标志 temp:validation_needed。
代码的演示部分模拟了如何使用此工具。它设置了内存会话服务并创建了具有一些预定义状态的初始会话。然后手动创建 ToolContext 以模拟 ADK Runner 执行工具的环境。使用此模拟上下文调用 log_user_login 函数。最后,代码再次检索会话以显示状态已通过工具的执行更新。目标是展示将状态更改封装在工具中如何使代码比直接在工具外部操作状态更清晰、更有组织。
请注意,强烈不建议在检索会话后直接修改 session.state 字典,因为它会绕过标准事件处理机制。这种直接更改不会记录在会话的事件历史中,可能不会被选定的 SessionService 持久化,可能导致并发问题,并且不会更新时间戳等基本元数据。更新会话状态的推荐方法是在 LlmAgent 上使用 output_key 参数(专门用于智能体最终文本响应)或在通过 session_service.append_event() 追加事件时在 EventActions.state_delta 中包含状态更改。session.state 应主要用于读取现有数据。
总而言之,在设计状态时,保持简单,使用基本数据类型,为键提供清晰的名称并正确使用前缀,避免深度嵌套,并始终使用 append_event 过程更新状态。
Memory:使用 MemoryService 的长期知识
在智能体中,Session 组件维护当前聊天历史(events)和特定于单个对话的临时数据(state)的记录。然而,为使智能体在交互中保留信息或访问外部数据,需要长期知识管理。这由 MemoryService 促进实现
1
2
3
4
5
6
## 示例:使用 InMemoryMemoryService
## 这适用于不需要跨应用程序重启数据持久性的本地开发和测试
## 应用停止时内存内容会丢失
from google.adk.memory import InMemoryMemoryService
memory_service = InMemoryMemoryService()
Session 和 State 可概念化为单个聊天会话的短期记忆,而由 MemoryService 管理的长期知识则充当持久且可搜索的存储库。此存储库可能包含来自多个过往交互或外部来源的信息。由 BaseMemoryService 接口定义的 MemoryService 为管理这种可搜索的长期知识建立了标准。其主要功能包括添加信息(涉及从会话中提取内容并使用 add_session_to_memory 方法存储)以及检索信息(允许智能体存储并使用 search_memory 方法接收相关数据)
ADK 提供了几种实现来创建这种长期知识存储。InMemoryMemoryService 提供适合测试目的的临时存储解决方案,但数据不会在应用重启后保留。对于生产环境,通常使用 VertexAiRagMemoryService。此服务利用 Google Cloud 的检索增强生成(RAG)服务,实现可扩展、持久和语义搜索功能(另请参阅第 14 章关于 RAG)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
## 示例:使用 VertexAiRagMemoryService
## 这适用于 GCP 上的可扩展生产,利用
## Vertex AI RAG(检索增强生成)实现持久的、
## 可搜索的记忆。
## 需要:pip install google-adk[vertexai],GCP
## 设置/身份验证和 Vertex AI RAG Corpus。
from google.adk.memory import VertexAiRagMemoryService
## 您的 Vertex AI RAG Corpus 的资源名称
RAG_CORPUS_RESOURCE_NAME = "projects/your-gcp-project-id/locations/us-central1/ragCorpora/your-corpus-id" # 替换为您的 Corpus 资源名称
## 检索行为的可选配置
SIMILARITY_TOP_K = 5 # 要检索的顶部结果数
VECTOR_DISTANCE_THRESHOLD = 0.7 # 向量相似度阈值
memory_service = VertexAiRagMemoryService(
rag_corpus=RAG_CORPUS_RESOURCE_NAME,
similarity_top_k=SIMILARITY_TOP_K,
vector_distance_threshold=VECTOR_DISTANCE_THRESHOLD
)
## 使用此服务时,像 add_session_to_memory
## 和 search_memory 这样的方法将与指定的 Vertex AI
## RAG Corpus 交互。
实操代码:LangChain 和 LangGraph 中的记忆管理
在 LangChain 和 LangGraph 中,Memory 是创建智能自然对话应用的关键组件。它使 AI 智能体能够记住过去交互信息、从反馈中学习并适应用户偏好。LangChain 的记忆功能通过引用存储历史来丰富当前提示词,然后记录最新交换供将来使用,从而提供此基础。随着智能体执行复杂任务,这种能力对效率和用户满意度变得至关重要
短期记忆: 这是线程范围的,意味着它跟踪单个会话或线程内正在进行的对话。它提供即时上下文,但完整历史可能挑战 LLM 的上下文窗口,导致错误或性能下降。LangGraph 将短期记忆作为智能体的一部分管理,该状态通过检查点器持久化,允许随时恢复线程
长期记忆: 存储跨会话的用户特定或应用级数据,在对话线程间共享。它保存在自定义”命名空间”中,可在任何线程的任何时间调用。LangGraph 提供存储来保存和调用长期记忆,使智能体能够无限期保留知识
LangChain 提供了多种工具管理对话历史,从手动控制到链内自动集成
ChatMessageHistory:手动记忆管理 对于在正式链外直接简单控制对话历史,ChatMessageHistory 类是理想选择。它允许手动跟踪对话交换
1
2
3
4
5
6
7
8
9
10
11
from langchain.memory import ChatMessageHistory
## 初始化历史对象
history = ChatMessageHistory()
## 添加用户和 AI 消息
history.add_user_message("我下周要去纽约。")
history.add_ai_message("太好了!这是一个很棒的城市。")
## 访问消息列表
print(history.messages)
ConversationBufferMemory:链的自动化记忆。要将记忆直接集成到链中,ConversationBufferMemory 是一个常见的选择。它保存对话的缓冲区并使其可用于您的提示词。其行为可以通过两个关键参数自定义:
- memory_key:指定提示词中将保存聊天历史的变量名的字符串。默认为”history”。
- return_messages:决定历史格式的布尔值。
- 如果为 False(默认),它返回单个格式化字符串,这对于标准 LLM 是理想的。
- 如果为 True,它返回消息对象列表,这是聊天模型的推荐格式。
1
2
3
4
5
6
7
8
9
10
from langchain.memory import ConversationBufferMemory
## 初始化记忆
memory = ConversationBufferMemory()
## 保存对话轮次
memory.save_context({"input": "天气怎么样?"}, {"output": "今天是晴天。"})
## 将记忆作为字符串加载
print(memory.load_memory_variables({}))
将此记忆集成到 LLMChain 中允许模型访问对话的历史并提供上下文相关的响应
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
from langchain_openai import OpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.memory import ConversationBufferMemory
## 1. 定义 LLM 和提示词
llm = OpenAI(temperature=0)
template = """你是一个有帮助的旅行代理。
之前的对话:
{history}
新问题:{question}
响应:"""
prompt = PromptTemplate.from_template(template)
## 2. 配置记忆
## memory_key "history" 与提示词中的变量匹配
memory = ConversationBufferMemory(memory_key="history")
## 3. 构建链
conversation = LLMChain(llm=llm, prompt=prompt, memory=memory)
## 4. 运行对话
response = conversation.predict(question="我想预订航班。")
print(response)
response = conversation.predict(question="顺便说一下,我叫 Sam。")
print(response)
response = conversation.predict(question="我的名字是什么?")
print(response)
为了提高聊天模型的有效性,建议通过设置 return_messages=True 使用消息对象的结构化列表。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
from langchain_openai import ChatOpenAI
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
from langchain_core.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
## 1. 定义聊天模型和提示词
llm = ChatOpenAI()
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template("你是一个友好的助手。"),
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
## 2. 配置记忆
## return_messages=True 对于聊天模型是必不可少的
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
## 3. 构建链
conversation = LLMChain(llm=llm, prompt=prompt, memory=memory)
## 4. 运行对话
response = conversation.predict(question="嗨,我是 Jane。")
print(response)
response = conversation.predict(question="你记得我的名字吗?")
print(response)
长期记忆类型:长期记忆允许系统在不同对话中保留信息,提供更深层次上下文和个性化。可分解为类似人类记忆的三种类型:
- 语义记忆:记住事实 涉及保留特定事实和概念,如用户偏好或领域知识。用于为智能体提供基础,带来更个性化和相关的交互。此信息可作为持续更新的用户”配置文件”(JSON 文档)或作为单个事实文档的”集合”管理
- 情景记忆:记住经历 涉及回忆过去事件或行动。对于 AI Agent,情景记忆通常用于记住如何完成任务。实践中常通过少样本示例提示实现,Agent 从过去成功交互序列中学习以正确执行任务
- 程序记忆:记住规则 关于如何执行任务的记忆——Agent 的核心指令和行为,通常包含在其系统提示中。Agent 修改自身提示以适应和改进很常见。有效技术是”反思”,其中智能体审查其当前指令和最近交互,然后被要求改进自身指令
下面是演示智能体使用反思来更新存储在 LangGraph BaseStore 中的程序记忆的伪代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
## 更新 agent 指令的节点
def update_instructions(state: State, store: BaseStore):
namespace = ("instructions",)
# 从存储中获取当前指令
current_instructions = store.search(namespace)[0]
# 创建提示词要求 LLM 反思对话
# 并生成新的、改进的指令
prompt = prompt_template.format(
instructions=current_instructions.value["instructions"],
conversation=state["messages"]
)
# 从 LLM 获取新指令
output = llm.invoke(prompt)
new_instructions = output['new_instructions']
# 将更新的指令保存回存储
store.put(("agent_instructions",), "agent_a", {"instructions": new_instructions})
## 使用指令生成响应的节点
def call_model(state: State, store: BaseStore):
namespace = ("agent_instructions", )
# 从存储中检索最新指令
instructions = store.get(namespace, key="agent_a")[0]
# 使用检索到的指令格式化提示词
prompt = prompt_template.format(instructions=instructions.value["instructions"])
# ... 应用程序逻辑继续
LangGraph 将长期记忆存储为存储中的 JSON 文档。每个记忆都在自定义命名空间(如文件夹)和不同的键(如文件名)下组织。这种分层结构便于组织和检索信息。以下代码演示了如何使用 InMemoryStore 放置、获取和搜索记忆。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
from langgraph.store.memory import InMemoryStore
## 真实嵌入函数的占位符
def embed(texts: list[str]) -> list[list[float]]:
# 在真实应用程序中,使用适当的嵌入模型
return [[1.0, 2.0] for _ in texts]
## 初始化记忆存储。对于生产,使用数据库支持的存储。
store = InMemoryStore(index={"embed": embed, "dims": 2})
## 为特定用户和应用程序上下文定义命名空间
user_id = "my-user"
application_context = "chitchat"
namespace = (user_id, application_context)
## 1. 将记忆放入存储
store.put(
namespace,
"a-memory", # 此记忆的键
{
"rules": [
"用户喜欢简短、直接的语言",
"用户只说英语和 python",
],
"my-key": "my-value",
},
)
## 2. 通过其命名空间和键获取记忆
item = store.get(namespace, "a-memory")
print("检索的项目:", item)
## 3. 在命名空间内搜索记忆,按内容过滤
## 并按与查询的向量相似度排序。
items = store.search(
namespace,
filter={"my-key": "my-value"},
query="语言偏好"
)
print("搜索结果:", items)
Vertex Memory Bank(记忆库)
Memory Bank 是 Vertex AI Agent Engine 的托管服务,为智能体提供长期记忆。该服务使用 Gemini 模型异步分析对话历史,提取关键事实和用户偏好。
此信息持久存储,按定义范围(如用户 ID)组织,并智能更新(整合新数据、解决矛盾)。开始新会话时,Agent 通过完整数据调用或嵌入相似度搜索检索相关记忆,实现跨会话连续性及基于回忆信息的个性化响应。
Agent 的 runner 与 VertexAiMemoryBankService 交互,后者需要先初始化。此服务处理智能体运行期间生成记忆的自动存储。每个记忆标记有唯一的 USER_ID 和 APP_NAME,确保将来能准确检索
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
from google.adk.memory import VertexAiMemoryBankService
agent_engine_id = agent_engine.api_resource.name.split("/")[-1]
memory_service = VertexAiMemoryBankService(
project="PROJECT_ID",
location="LOCATION",
agent_engine_id=agent_engine_id
)
session = await session_service.get_session(
app_name=app_name,
user_id="USER_ID",
session_id=session.id
)
await memory_service.add_session_to_memory(session)
Memory Bank 提供与 Google ADK 的无缝集成,提供即开即用的体验。对于使用其他智能体框架(如 LangGraph 和 CrewAI)的用户,Memory Bank 还通过直接 API 调用提供支持。演示这些集成的在线代码示例可供感兴趣的读者使用
速览
问题背景:智能体需要记住过去交互信息以执行复杂任务并提供连贯体验。缺乏记忆机制时,Agent 无法维护对话上下文、从经验中学习或提供个性化响应,被限制在简单的一次性交互中,无法处理多步骤过程或变化需求。核心问题是如何有效管理单个对话的即时临时信息和随时间积累的持久知识。
解决方案: 标准化解决方案是实现区分短期和长期存储的双组件记忆系统:短期上下文记忆在 LLM 窗口内保存最近交互以维护对话流;长期记忆使用外部数据库(如向量存储)实现高效的语义检索。Google ADK 等框架提供特定组件来管理此过程(如 Session 管理对话线程,State 处理临时数据)。专用的 MemoryService 与长期知识库交互,允许智能体将相关的过去信息纳入当前上下文。
实践建议: 当智能体做更多事情(不仅是回答单个问题)时使用此模式。对于需维护对话上下文、跟踪多步骤任务进度或通过回忆用户偏好历史来提供个性化交互的 Agent,此模式必不可少。当智能体从过去的成功/失败或新信息中学习并适应时,应实现记忆管理。
可视化摘要
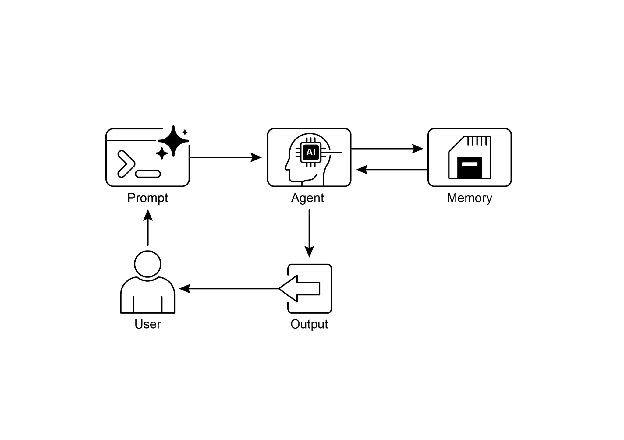
图 1:记忆管理设计模式
关键要点
快速回顾记忆管理的核心要点:
- 记忆对于智能体处理事务、学习和个性化交互至关重要
- 对话式 AI 依赖单个聊天中即时上下文的短期记忆和跨多个会话持久知识的长期记忆
- 短期记忆(即时信息)是临时的,通常受 LLM 上下文窗口或框架传递上下文方式的限制
- 长期记忆(持久信息)使用向量数据库等外部存储跨不同聊天保存信息,并通过搜索访问
- 像 ADK 这样的框架具有特定部分,如 Session(聊天线程)、State(临时聊天数据)和 MemoryService(可搜索的长期知识)来管理记忆
- ADK 的 SessionService 处理聊天会话的整个生命周期,包括其历史(events)和临时数据(state)
- ADK 的 session.state 是临时聊天数据的字典。前缀(user:、app:、temp:)指示数据归属位置及是否持久
- 在 ADK 中,应通过在添加事件时使用 EventActions.state_delta 或 output_key 更新状态,而非直接更改状态字典
- ADK 的 MemoryService 用于将信息放入长期存储并让智能体检索,通常使用工具
- LangChain 提供如 ConversationBufferMemory 的实用工具,自动将单个对话历史注入提示,使智能体回忆即时上下文
- LangGraph 通过使用存储来保存和检索跨不同用户会话的语义事实、情景经验甚至可更新的程序规则,实现高级长期记忆
- Memory Bank 是托管服务,通过自动提取、存储和调用用户特定信息为智能体提供持久长期记忆,在 Google 的 ADK、LangGraph 和 CrewAI 等框架中实现个性化的持续对话
结论
本章深入探讨智能体记忆管理,展示了短暂上下文与长期持久知识之间的区别。我们讨论了这些记忆类型的设置方式以及在构建更智能智能体中的应用。详细了解了 Google ADK 如何通过 Session、State 和 MemoryService 等组件处理此过程。既然已介绍智能体如何管理记忆(短期和长期),我们将继续探讨其如何学习和适应。下一模式”学习和适应”关注智能体如何根据智能体数据改变思考、行动或知识。
参考文献
- ADK Memory, https://google.github.io/adk-docs/sessions/memory/
- LangGraph Memory, https://langchain-ai.github.io/langgraph/concepts/memory/
- Vertex AI Agent Engine Memory Bank, https://cloud.google.com/blog/products/ai-machine-learning/vertex-ai-memory-bank-in-public-preview