第 5 章:工具使用
工具使用模式概述
截至目前,我们探讨的智能体模式主要聚焦于编排语言模型间的交互以及管理智能体内部工作流的信息流(提示词链、路由、并行化、反思)。然而,要让智能体真正发挥作用并与现实世界或外部系统交互,它们需要具备使用工具的能力。
工具使用模式通常通过函数调用(Function Calling)机制实现,使智能体能够与外部 API、数据库、服务交互,甚至执行代码。该机制让位于智能体核心的大语言模型(LLM)能根据用户请求或任务当前状态,决定何时以及如何调用特定的外部函数。
该过程通常包括:
- 工具定义: 向 LLM 定义并描述外部函数或能力。描述内容包括函数的用途、名称,以及它接受的参数及其类型和描述。
- LLM 决策: LLM 接收用户的请求和可用的工具定义。基于其对请求和工具的理解,LLM 决定是否需要调用一个或多个工具来满足请求。
- 函数调用生成: 如果 LLM 决定使用工具,它会生成结构化输出(通常是 JSON 对象),指定要调用的工具名称和要传递给它的参数,这些参数从用户请求中提取。
- 工具执行: 智能体框架或编排层拦截此结构化输出。它识别请求的工具并使用提供的参数执行实际的外部函数。
- 观察/结果: 工具执行的输出或结果返回给智能体。
- LLM 处理(可选但常见): LLM 接收工具的输出作为上下文,并使用它向用户制定最终响应或决定工作流中的下一步(可能涉及调用另一个工具、反思或提供最终答案)。
该模式是基础性的,因为它打破了 LLM 训练数据的限制,允许它访问最新信息、执行内部无法完成的计算、与用户特定数据交互或触发现实世界的行动。工具调用是连接 LLM 推理能力与大量可用外部功能之间差距的技术机制。
虽然”函数调用”准确描述了调用预定义代码函数的过程,但采用更广泛的”工具调用”概念更具实践价值。这一更宽泛的术语承认智能体的能力可以远超简单函数执行范畴——”工具”既可以是传统函数,也可以是复杂的 API 端点、数据库查询请求,甚至是向其他专业智能体发出的指令。这种视角帮助我们构建更复杂的系统,例如主智能体可以将复杂数据分析任务委托给专用的”分析师智能体”,或通过 API 查询外部知识库。从”工具调用”的角度思考,能更好地把握智能体作为跨多样化数字资源和其他智能实体生态系统编排者的全部潜力。
像 LangChain、LangGraph 和 Google 智能体开发工具包(ADK)这样的框架为定义工具并将它们集成到智能体工作流提供了强大支持,通常利用现代 LLM(如 Gemini 或 OpenAI 系列中的模型)的原生函数调用能力。在这些框架的”画布”上,您定义工具,然后配置智能体(通常是 LLM 智能体)以了解并能够使用这些工具。
工具使用是构建强大、交互式且具外部环境感知能力的智能体的基石模式。
实际应用与用例
工具使用模式几乎适用于智能体超越生成文本来执行操作或检索特定动态信息的任何场景:
- 从外部源检索信息: 访问 LLM 训练数据中不存在的实时数据或信息。
- 用例: 天气智能体。
- 工具: 接受位置并返回当前天气状况的天气 API。
- 智能体流程: 用户问”伦敦的天气如何?”,LLM 识别需要天气工具,用”伦敦”调用工具,工具返回数据,LLM 将数据格式化为用户友好的响应。
- 与数据库和 API 交互: 对结构化数据执行查询、更新或其他操作。
- 用例: 电子商务智能体。
- 工具: API 调用以检查产品库存、获取订单状态或处理付款。
- 智能体流程: 用户问”产品 X 有库存吗?”,LLM 调用库存 API,工具返回库存数量,LLM 告诉用户库存状态。
- 执行计算和数据分析: 使用外部计算器、数据分析库或统计工具。
- 用例: 金融智能体。
- 工具: 计算器函数、股票市场数据 API、电子表格工具。
- 智能体流程: 用户问”AAPL 的当前价格是多少,如果我以 150 美元购买 100 股,计算潜在利润?”,LLM 调用股票 API,获取当前价格,然后调用计算器工具,获取结果,格式化响应。
- 发送通信: 发送电子邮件、消息或对外部通信服务进行 API 调用。
- 用例: 个人助理智能体。
- 工具: 电子邮件发送 API。
- 智能体流程: 用户说”给 John 发一封关于明天会议的电子邮件。”,LLM 使用从请求中提取的收件人、主题和正文调用电子邮件工具。
- 执行代码: 在安全环境中运行代码片段以执行特定任务。
- 用例: 编码助手智能体。
- 工具: 代码解释器。
- 智能体流程: 用户提供 Python 代码片段并问”这段代码做什么?”,LLM 使用解释器工具运行代码并分析其输出。
- 控制其他系统或设备: 与智能家居设备、物联网平台或其他连接系统交互。
- 用例: 智能家居智能体。
- 工具: 控制智能灯的 API。
- 智能体流程: 用户说”关闭客厅的灯。”LLM 使用命令和目标设备调用智能家居工具。
工具使用正是将语言模型从文本生成器转变为能够在数字或物理世界中感知、推理和行动的智能体的关键(见图 1)。
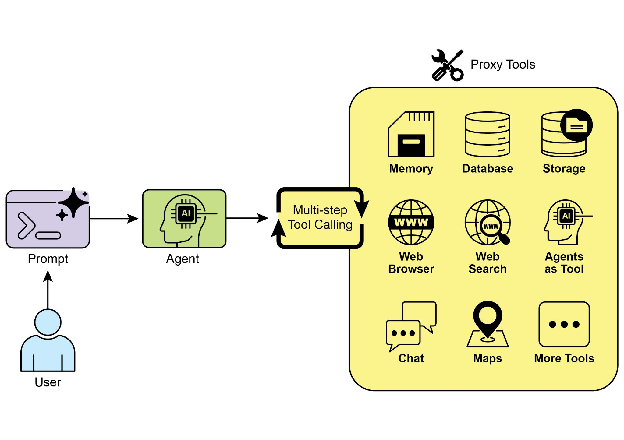
图 1:智能体使用工具的一些示例
实操代码示例(LangChain)
在 LangChain 框架中实现工具使用分为两个阶段。首先,定义一个或多个工具,通常通过封装现有的 Python 函数或其他可运行组件。随后,将这些工具与语言模型绑定,从而使模型能够在确定需要调用外部函数来满足用户查询时,生成结构化的工具使用请求。
以下实现将通过首先定义一个简单函数来模拟信息检索工具,以此演示此原理。随后,将构建并配置一个智能体,利用此工具响应用户输入。执行此示例需要安装核心 LangChain 库和特定于模型的提供程序包。此外,使用所选语言模型服务进行适当的身份验证(通常通过在本地环境中配置的 API 密钥)是必要的先决条件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
import os, getpass
import asyncio
import nest_asyncio
from typing import List
from dotenv import load_dotenv
import logging
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.tools import tool as langchain_tool
from langchain.agents import create_tool_calling_agent, AgentExecutor
## 安全地提示用户并将 API 密钥设置为环境变量
## 安全地提示用户并将 API 密钥设置为环境变量
os.environ["GOOGLE_API_KEY"] = getpass.getpass("Enter your Google API key: ")
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter your OpenAI API key: ")
try:
# 需要具有函数/工具调用能力的模型。
llm = ChatGoogleGenerativeAI(model="gemini-2.0-flash", temperature=0)
print(f"✅ 语言模型已初始化:{llm.model}")
except Exception as e:
print(f"🛑 初始化语言模型时出错:{e}")
llm = None
## --- 定义工具 ---
@langchain_tool
def search_information(query: str) -> str:
"""提供有关给定主题的事实信息。使用此工具查找诸如"法国首都"或"伦敦的天气?"等短语的答案。
"""
print(f"\n--- 🛠️ 工具调用:search_information,查询:'{query}' ---")
# 使用预定义结果字典模拟搜索工具。
simulated_results = {
"weather in london": "伦敦目前多云,温度为 15°C。",
"capital of france": "法国的首都是巴黎。",
"population of earth": "地球的估计人口约为 80 亿人。",
"tallest mountain": "珠穆朗玛峰是海拔最高的山峰。",
"default": f"'{query}' 的模拟搜索结果:未找到特定信息,但该主题似乎很有趣。"
}
result = simulated_results.get(query.lower(), simulated_results["default"])
print(f"--- 工具结果:{result} ---")
return result
tools = [search_information]
## --- 创建工具调用智能体 ---
if llm:
# 此提示词模板需要一个 `agent_scratchpad` 占位符用于智能体的内部步骤。
agent_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个有用的助手。"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
])
# 创建智能体,将 LLM、工具和提示词绑定在一起。
agent = create_tool_calling_agent(llm, tools, agent_prompt)
# AgentExecutor 是调用智能体并执行所选工具的运行时。
# 这里不需要 'tools' 参数,因为它们已经绑定到智能体。
agent_executor = AgentExecutor(agent=agent, verbose=True, tools=tools)
async def run_agent_with_tool(query: str):
"""使用查询调用智能体执行器并打印最终响应。"""
print(f"\n--- 🏃 使用查询运行智能体:'{query}' ---")
try:
response = await agent_executor.ainvoke({"input": query})
print("\n--- ✅ 最终智能体响应 ---")
print(response["output"])
except Exception as e:
print(f"\n🛑 智能体执行期间发生错误:{e}")
async def main():
"""并发运行所有智能体查询。"""
tasks = [
run_agent_with_tool("法国的首都是什么?"),
run_agent_with_tool("伦敦的天气怎么样?"),
run_agent_with_tool("告诉我一些关于狗的事情。") # 应该触发默认工具响应
]
await asyncio.gather(*tasks)
nest_asyncio.apply()
asyncio.run(main())
代码使用 LangChain 库和 Google Gemini 模型设置了一个工具调用智能体。它定义了一个 search_information 工具,模拟为特定查询提供事实答案。该工具对”weather in london”、”capital of france”和”population of earth”有预定义响应,以及其他查询的默认响应。初始化了一个 ChatGoogleGenerativeAI 模型,确保其具有工具调用能力。创建了一个 ChatPromptTemplate 来指导智能体的交互。使用 create_tool_calling_agent 函数将语言模型、工具和提示词组合成一个智能体。然后设置一个 AgentExecutor 来管理智能体的执行和工具调用。定义了 run_agent_with_tool 异步函数以使用给定查询调用智能体并打印结果。main 异步函数准备多个要并发运行的查询。这些查询旨在测试 search_information 工具的特定响应和默认响应。最后,asyncio.run(main()) 调用执行所有智能体任务。代码在继续进行智能体设置和执行之前,包含了对 LLM 初始化成功的检查。
实操代码示例(CrewAI)
此代码演示了在 CrewAI 框架中实现工具调用(工具)的具体案例。通过设置简单场景:让配备信息查询工具的智能体模拟股价,展示核心实现逻辑。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
## pip install crewai langchain-openai
import os
from crewai import Agent, Task, Crew
from crewai.tools import tool
import logging
## --- 最佳实践:配置日志 ---
## 基本日志设置有助于调试和跟踪团队的执行。
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
## --- 设置您的 API 密钥 ---
## 对于生产环境,建议使用更安全的密钥管理方法
## 例如在运行时加载的环境变量或秘密管理器。
#
## 为您选择的 LLM 提供商设置环境变量(例如,OPENAI_API_KEY)
## os.environ["OPENAI_API_KEY"] = "YOUR_API_KEY"
## os.environ["OPENAI_MODEL_NAME"] = "gpt-4o"
## --- 1. 重构的工具:返回干净的数据 ---
## 该工具现在返回原始数据(浮点数)或引发标准 Python 错误。
## 这使其更可重用,并强制智能体处理结果。
@tool("Stock Price Lookup Tool")
def get_stock_price(ticker: str) -> float:
"""
获取给定股票代码符号的最新模拟股票价格。
以浮点数形式返回价格。如果未找到代码,则引发 ValueError。
"""
logging.info(f"工具调用:get_stock_price,代码为 '{ticker}'")
simulated_prices = {
"AAPL": 178.15,
"GOOGL": 1750.30,
"MSFT": 425.50,
}
price = simulated_prices.get(ticker.upper())
if price is not None:
return price
else:
# 引发特定错误比返回字符串更好。
# 智能体具备处理异常的能力,可以决定下一步行动。
raise ValueError(f"未找到代码 '{ticker.upper()}' 的模拟价格。")
## --- 2. 定义智能体 ---
## 智能体保持不变,但它现在将利用改进的工具。
financial_analyst_agent = Agent(
role='高级财务分析师',
goal='使用提供的工具分析股票数据并报告关键价格。',
backstory="你是一位经验丰富的财务分析师,擅长使用数据源查找股票信息。你提供清晰、直接的答案。",
verbose=True,
tools=[get_stock_price],
# 允许委托可能很有用,但对于这个简单任务不是必需的。
allow_delegation=False,
)
## --- 3. 精炼任务:更清晰的说明和错误处理 ---
## 任务描述更具体,并指导智能体应对
## 成功的数据检索和潜在错误。
analyze_aapl_task = Task(
description=(
"Apple(代码:AAPL)的当前模拟股票价格是多少?"
"使用 'Stock Price Lookup Tool' 查找它。"
"如果未找到代码,你必须报告无法检索价格。"
),
expected_output=(
"一个清晰的句子,说明 AAPL 的模拟股票价格。"
"例如:'AAPL 的模拟股票价格是 $178.15。'"
"如果无法找到价格,请明确说明。"
),
agent=financial_analyst_agent,
)
## --- 4. 组建团队 ---
## 团队协调智能体任务如何协同工作。
financial_crew = Crew(
agents=[financial_analyst_agent],
tasks=[analyze_aapl_task],
verbose=True # 在生产环境中设置为 False 以获得较少的详细日志
)
## --- 5. 在主执行块中运行团队 ---
## 使用 __name__ == "__main__": 块是标准 Python 最佳实践。
def main():
"""运行团队的主函数。"""
# 在启动前检查 API 密钥以避免运行时错误。
if not os.environ.get("OPENAI_API_KEY"):
print("错误:未设置 OPENAI_API_KEY 环境变量。")
print("请在运行脚本之前设置它。")
return
print("\n## 启动财务团队...")
print("---------------------------------")
# kickoff 方法启动执行。
result = financial_crew.kickoff()
print("\n---------------------------------")
print("## 团队执行完成。")
print("\n最终结果:\n", result)
if __name__ == "__main__":
main()
此代码演示了使用 CrewAI 库模拟财务分析任务的简单应用程序。它定义了一个自定义工具 get_stock_price,模拟查找预定义股票代码的价格。该工具设计为对有效代码返回浮点数,或对无效代码引发 ValueError。创建了一个名为 financial_analyst_agent 的 CrewAI Agent,角色为高级财务分析师。该智能体被赋予 get_stock_price 工具进行交互。定义了一个任务 analyze_aapl_task,专门指示智能体查找 AAPL 的模拟股票价格。任务描述包括关于使用工具时如何处理成功和失败情况的明确说明。组建了一个团队,包含 financial_analyst_agent 和 analyze_aapl_task。为智能体和团队设置详细日志,以在执行期间提供详细日志。脚本的主要部分在标准 if name == “main”: 块中使用 kickoff() 方法运行团队的任务。在启动团队之前,它会检查是否设置了 OPENAI_API_KEY 环境变量,这是智能体运行所必需的。最后将团队执行的结果(即任务的输出)打印到控制台。代码还包括基本日志配置,以更好地跟踪团队的行动和工具调用。它使用环境变量进行 API 密钥管理,尽管它指出对于生产环境建议使用更安全的方法。简而言之,核心逻辑展示了如何定义工具、Agent 和任务,以在 CrewAI 中创建协作工作流。
实操代码(Google ADK)
Google 智能体开发工具包 (ADK) 提供原生集成工具库,可直接扩展智能体的能力
Google 搜索: 此类组件的主要示例是 Google 搜索工具。此工具作为 Google 搜索引擎的直接接口,为智能体执行网络搜索和检索外部信息的功能。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
from google.adk.agents import Agent
from google.adk.runners import Runner
from google.adk.sessions import InMemorySessionService
from google.adk.tools import google_search
from google.genai import types
import nest_asyncio
import asyncio
## 定义会话设置和智能体所需的变量
APP_NAME="Google Search_agent"
USER_ID="user1234"
SESSION_ID="1234"
## 使用搜索工具定义智能体
root_agent = Agent(
name="basic_search_agent",
model="gemini-2.0-flash-exp",
description="使用 Google 搜索回答问题的智能体。",
instruction="我可以通过搜索互联网回答您的问题。随便问我什么!",
tools=[google_search] # Google 搜索是执行 Google 搜索的预构建工具。
)
## 智能体辅助函数
async def call_agent(query):
"""
使用查询调用智能体的辅助函数。
"""
# 会话和运行器
session_service = InMemorySessionService()
session = await session_service.create_session(app_name=APP_NAME, user_id=USER_ID, session_id=SESSION_ID)
runner = Runner(agent=root_agent, app_name=APP_NAME, session_service=session_service)
content = types.Content(role='user', parts=[types.Part(text=query)])
events = runner.run(user_id=USER_ID, session_id=SESSION_ID, new_message=content)
for event in events:
if event.is_final_response():
final_response = event.content.parts[0].text
print("智能体响应:", final_response)
nest_asyncio.apply()
asyncio.run(call_agent("最新的 AI 新闻是什么?"))
此代码演示了如何使用 Python 的 Google ADK 创建和使用由 Google ADK 驱动的基本智能体。该智能体为通过利用 Google 搜索作为工具来回答问题。首先,从 IPython、google.adk 和 google.genai 导入必要的库。定义了应用程序名称、用户 ID 和会话 ID 的常量。创建了一个名为”basic_search_agent”的智能体,具有描述和说明指示其目的。它被配置为使用 Google 搜索工具,这是 ADK 提供的预构建工具。初始化 InMemorySessionService(见第 8 章)以管理智能体的会话。为指定的应用程序、用户和会话 ID 创建新会话。实例化 Runner,将创建的智能体与会话服务链接此运行器负责在会话中执行智能体的交互。定义了一个名为 call_agent 的函数 以简化向智能体发送查询和处理响应。在 call_agent 内部,用户的查询被格式化为具有角色”user”的 types.Content 对象。使用用户 ID、会话 ID 和新消息内容调用 runner.run 方法。runner.run 方法返回表示智能体操作和响应的事件列表。遍历这些事件以查找最终响应。如果事件被识别为最终响应,则提取该响应的文本内容。提取的智能体响应然后打印到控制台。最后,使用查询”最新的 AI 新闻是什么?”调用 call_agent 函数以演示智能体的运行情况。
代码执行: Google ADK 包含专为动态代码执行设计的组件。built_in_code_execution 工具提供沙盒化 Python 解释器,让模型能编写运行代码执行计算、操作数据结构及运行脚本。此功能对需要确定性逻辑和精确计算的任务至关重要,弥补了概率性语言生成的不足。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
import os, getpass
import asyncio
import nest_asyncio
from typing import List
from dotenv import load_dotenv
import logging
from google.adk.agents import LlmAgent # Removed ADKAgent as it's deprecated
from google.adk.runners import Runner
from google.adk.sessions import InMemorySessionService
from google.adk.tools import google_search
from google.adk.code_executors import BuiltInCodeExecutor
from google.genai import types
## 定义会话设置和智能体所需的变量
APP_NAME = "calculator"
USER_ID = "user1234"
SESSION_ID = "session_code_exec_async"
## 智能体
code_agent = LlmAgent(
name="calculator_agent",
model="gemini-2.0-flash",
code_executor=BuiltInCodeExecutor(),
instruction="""你是一个计算器智能体。
当给定数学表达式时,编写并执行 Python 代码来计算结果。
仅返回最终的数值结果作为纯文本,不带 markdown 或代码块。
""",
description="执行 Python 代码以进行计算。",
)
## 智能体辅助函数(异步)
async def call_agent_async(query):
# 会话和运行器
session_service = InMemorySessionService()
session = await session_service.create_session(app_name=APP_NAME, user_id=USER_ID, session_id=SESSION_ID)
runner = Runner(agent=code_agent, app_name=APP_NAME, session_service=session_service)
content = types.Content(role='user', parts=[types.Part(text=query)])
print(f"\n--- 运行查询:{query} ---")
final_response_text = "未捕获最终文本响应。"
try:
# 使用 run_async
async for event in runner.run_async(user_id=USER_ID, session_id=SESSION_ID, new_message=content):
print(f"事件 ID:{event.id},作者:{event.author}")
# --- 首先检查特定部分 ---
# has_specific_part = False
if event.content and event.content.parts and event.is_final_response():
for part in event.content.parts: # 遍历所有部分
if part.executable_code:
# 通过 .code 访问实际代码字符串
print(f" 调试:智能体生成的代码:\n```python\n{part.executable_code.code}\n```")
# has_specific_part = True # Removed as it's not used
elif part.code_execution_result:
# 正确访问结果和输出
print(f" 调试:代码执行结果:{part.code_execution_result.outcome} - 输出:\n{part.code_execution_result.output}")
# has_specific_part = True # Removed as it's not used
# 也打印在任何事件中找到的任何文本部分以进行调试
elif part.text and not part.text.isspace():
print(f" 文本:'{part.text.strip()}'")
# 不要在这里设置 has_specific_part=True,因为我们希望下面的最终响应逻辑
# --- 在特定部分之后检查最终响应 ---
text_parts = [part.text for part in event.content.parts if part.text]
final_result = "".join(text_parts)
print(f"==> 最终智能体响应:{final_result}")
except Exception as e:
print(f"智能体运行期间出错:{e}")
print("-" * 30)
## 运行示例的主异步函数
async def main():
await call_agent_async("计算 (5 + 7) * 3 的值")
await call_agent_async("10 的阶乘是多少?")
## 执行主异步函数
try:
nest_asyncio.apply()
asyncio.run(main())
except RuntimeError as e:
# 在已运行的循环中运行 asyncio.run 时处理特定错误(如 Jupyter/Colab)
if "cannot be called from a running event loop" in str(e):
print("\n在现有事件循环中运行(如 Colab/Jupyter)。")
print("请在笔记本单元格中运行 `await main()` 代替。")
# 如果在交互式环境(如笔记本)中,您可能需要运行:
# await main()
else:
raise e # 重新引发其他运行时错误
此脚本使用 Google 的智能体开发工具包(ADK)创建一个通过编写和执行 Python 代码解决数学问题的智能体。它定义了一个 LlmAgent,专门指示其充当计算器,为其配备 built_in_code_execution 工具。主要逻辑位于 call_agent_async 函数中,该函数向智能体发送用户查询并处理结果事件。在此函数内部,异步循环遍历事件,打印生成的 Python 代码及其执行结果以进行调试。代码仔细区分这些中间步骤和包含数值答案的最终事件。最后,main 函数使用两个不同的数学表达式运行智能体,以演示其执行计算的能力。
企业搜索: 此代码使用 Python 中的 google.adk 库定义了一个 Google ADK 应用程序。它专门使用 VSearchAgent,该智能体通过搜索指定的 Vertex AI 搜索数据存储来回答问题。代码初始化一个名为”q2_strategy_vsearch_agent”的 VSearchAgent,提供描述、要使用的模型(”gemini-2.0-flash-exp”)和 Vertex AI 搜索数据存储的 ID。DATASTORE_ID 预期设置为环境变量。然后为智能体设置 Runner,使用 InMemorySessionService 管理对话历史。定义了异步函数 call_vsearch_agent_async 以与智能体交互。它接受查询,构造消息内容对象,并调用运行器的 run_async 方法将查询发送到智能体。然后该函数将智能体的响应流式传输到控制台。它还打印有关最终响应的信息,包括来自数据存储的任何来源归因。包含错误处理以捕获智能体执行期间的异常,并提供有关潜在问题(如数据存储 ID 不正确或缺少权限)的信息性消息。提供了另一个异步函数 run_vsearch_example 以演示如何使用示例查询调用智能体。主执行块检查 DATASTORE_ID 是否已设置,然后使用 asyncio.run 运行示例。它包括检查以处理在已有运行事件循环的环境(如 Jupyter 笔记本)中运行代码的情况。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
import asyncio
from google.genai import types
from google.adk import agents
from google.adk.runners import Runner
from google.adk.sessions import InMemorySessionService
import os
## --- 配置 ---
## 确保您已设置 GOOGLE_API_KEY 和 DATASTORE_ID 环境变量
## 例如:
## os.environ["GOOGLE_API_KEY"] = "YOUR_API_KEY"
## os.environ["DATASTORE_ID"] = "YOUR_DATASTORE_ID"
DATASTORE_ID = os.environ.get("DATASTORE_ID")
## --- 应用程序常量 ---
APP_NAME = "vsearch_app"
USER_ID = "user_123" # 示例用户 ID
SESSION_ID = "session_456" # 示例会话 ID
## --- 智能体(根据指南的示例更新) ---
vsearch_agent = agents.VSearchAgent(
name="q2_strategy_vsearch_agent",
description="使用 Vertex AI 搜索回答有关 Q2 战略文档的问题。",
model="gemini-2.0-flash-exp", # 根据指南示例更新模型
datastore_id=DATASTORE_ID,
model_parameters={"temperature": 0.0}
)
## --- 运行器和会话初始化 ---
runner = Runner(
agent=vsearch_agent,
app_name=APP_NAME,
session_service=InMemorySessionService(),
)
## --- 智能体逻辑 ---
async def call_vsearch_agent_async(query: str):
"""初始化会话并流式传输智能体响应。"""
print(f"用户:{query}")
print("Agent:", end="", flush=True)
try:
# 正确构造消息内容
content = types.Content(role='user', parts=[types.Part(text=query)])
# 从异步运行器处理到达的事件
async for event in runner.run_async(
user_id=USER_ID,
session_id=SESSION_ID,
new_message=content
):
# 用于响应文本的逐令牌流式传输
if hasattr(event, 'content_part_delta') and event.content_part_delta:
print(event.content_part_delta.text, end="", flush=True)
# 处理最终响应及其关联的元数据
if event.is_final_response():
print() # 流式响应后换行
if event.grounding_metadata:
print(f" (来源归因:找到 {len(event.grounding_metadata.grounding_attributions)} 个来源)")
else:
print(" (未找到基础元数据)")
print("-" * 30)
except Exception as e:
print(f"\n发生错误:{e}")
print("请确保您的数据存储 ID 正确,并且服务帐户具有必要的权限。")
print("-" * 30)
## --- 运行示例 ---
async def run_vsearch_example():
# 替换为与您的数据存储内容相关的问题
await call_vsearch_agent_async("总结 Q2 战略文档的要点。")
await call_vsearch_agent_async("实验室 X 提到了哪些安全程序?")
## --- 执行 ---
if __name__ == "__main__":
if not DATASTORE_ID:
print("错误:未设置 DATASTORE_ID 环境变量。")
else:
try:
asyncio.run(run_vsearch_example())
except RuntimeError as e:
# 这处理在已有运行事件循环的环境中调用 asyncio.run 的情况
# (如 Jupyter 笔记本)。
if "cannot be called from a running event loop" in str(e):
print("在运行事件循环中跳过执行。请直接运行此脚本。")
else:
raise e
总的来说,此代码为构建利用 Vertex AI Search 根据存储在数据存储中的信息回答问题的对话式 AI 应用程序提供了基本框架。它演示了如何定义智能体、设置运行器以及在流式传输响应的同时异步与智能体交互。重点是从特定数据存储检索和综合信息以回答用户查询。
Vertex Extensions: Vertex AI 扩展是一个结构化的 API 包装器,使模型能够连接到外部 API 以进行实时数据处理和操作执行。扩展提供企业级安全性、数据隐私和性能保证。它们可用于生成和运行代码、查询网站以及分析来自私有数据存储的信息等任务。Google 为常见用例提供预构建扩展,如代码解释器和 Vertex AI Search,并可选择创建自定义扩展。扩展的主要好处包括强大的企业控制和与其他 Google 产品的无缝集成。扩展和工具调用之间的关键区别在于它们的执行:Vertex AI 自动执行扩展,而工具调用需要用户或客户端手动执行。
速览
问题背景: 大型语言模型(LLM)是强大的文本生成器,但它们基本上与外部世界断开连接。它们的知识是静态的,仅限于训练数据,并且缺乏执行操作或检索实时信息的能力。这种固有的限制阻止它们完成需要与外部 API、数据库或服务交互的任务。没有通往这些外部系统的桥梁,它们解决现实世界问题的效用受到严重限制。
解决方案: 工具使用模式(通常通过工具调用实现)为此问题提供了标准化解决方案。它的工作原理是以 LLM 可以理解的方式向其描述可用的外部函数或”工具”。基于用户的请求,智能体 LLM 可以决定是否需要工具,并生成指定要调用哪个函数以及使用什么参数的结构化数据对象(如 JSON)。编排层执行此工具调用,检索结果,并将其反馈给 LLM。这允许 LLM 将最新的外部信息或操作结果合并到其最终响应中,有效地赋予其行动能力。
实践建议: 当智能体需要突破 LLM 的内部知识并与外部世界交互时,使用工具使用模式。这对于需要实时数据(例如,检查天气、股票价格)、访问私有或专有信息(例如,查询公司数据库)、执行精确计算、执行代码或触发其他系统中的操作(例如,发送电子邮件、控制智能设备)的任务至关重要。
可视化摘要:
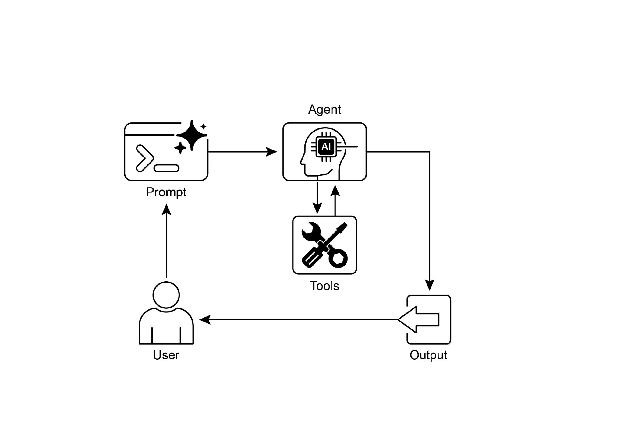
图 2:工具使用设计模式
关键要点
- 工具使用(函数调用)允许智能体与外部系统交互并访问动态信息。
- 它涉及定义具有 LLM 可以理解的清晰描述和参数的工具。
- LLM 决定何时使用工具并生成结构化工具调用。
- 智能体框架执行实际的工具调用并将结果返回给 LLM。
- 工具使用对于构建可以执行现实世界操作并提供最新信息的智能体至关重要。
- LangChain 使用 @tool 装饰器简化工具定义,并提供 create_tool_calling_agent 和 AgentExecutor 用于构建工具使用智能体。
- Google ADK 有许多非常有用的预构建工具,如 Google 搜索、代码执行和 Vertex AI 搜索工具。
结论
工具使用模式是将大型语言模型的功能范围扩展到其固有文本生成能力之外的关键架构原则。通过为模型配备与外部软件和数据源交互的能力,此范式允许智能体执行操作、进行计算并从其他系统检索信息。此过程涉及模型在确定满足用户查询需要时生成调用外部工具的结构化请求。LangChain、Google ADK 和 CrewAI 等框架提供结构化抽象和组件,促进这些外部工具的集成。这些框架管理向模型公开工具规范并解析其后续工具使用请求的过程。这简化了可以与外部数字环境交互并在其中采取行动的复杂智能体系统的开发。
参考文献
- LangChain Documentation (Tools): https://python.langchain.com/docs/integrations/tools/
- Google 智能体开发工具包 (ADK) 文档 (工具): https://google.github.io/adk-docs/tools/
- OpenAI Function Calling Documentation: https://platform.openai.com/docs/guides/function-calling
- CrewAI Documentation (Tools): https://docs.crewai.com/concepts/tools