Chapter 11: Goal Setting and Monitoring
第 11 章:目标设定与监控
For AI agents to be truly effective and purposeful, they need more than just the ability to process information or use tools; they need a clear sense of direction and a way to know if they’re actually succeeding. This is where the Goal Setting and Monitoring pattern comes into play. It’s about giving agents specific objectives to work towards and equipping them with the means to track their progress and determine if those objectives have been met.
要使 AI 智能体真正有效且有目的性,它们不仅需要处理信息或使用工具的能力,还需要明确的方向感和判断自身是否真正成功的方法。这就是目标设定与监控模式发挥作用的地方。该模式的核心是为智能体设定具体的工作目标,并为其配备跟踪进度和确定这些目标是否已实现的手段。
Goal Setting and Monitoring Pattern Overview
目标设定与监控速览
Think about planning a trip. You don’t just spontaneously appear at your destination. You decide where you want to go (the goal state), figure out where you are starting from (the initial state), consider available options (transportation, routes, budget), and then map out a sequence of steps: book tickets, pack bags, travel to the airport/station, board the transport, arrive, find accommodation, etc. This step-by-step process, often considering dependencies and constraints, is fundamentally what we mean by planning in agentic systems.
设想规划一次旅行。你不会凭空出现在目的地。你需要决定想去哪里(目标状态),弄清楚从哪里出发(初始状态),考虑可用选项(交通工具、路线、预算),然后制定一系列步骤:订票、打包行李、前往机场/车站、登机/上车、抵达、找住宿等。这个逐步的过程,通常会考虑依赖关系和约束条件,本质上就是我们在智能体系统中所说的规划。
In the context of AI agents, planning typically involves an agent taking a high-level objective and autonomously, or semi-autonomously, generating a series of intermediate steps or sub-goals. These steps can then be executed sequentially or in a more complex flow, potentially involving other patterns like tool use, routing, or multi-agent collaboration. The planning mechanism might involve sophisticated search algorithms, logical reasoning, or increasingly, leveraging the capabilities of large language models (LLMs) to generate plausible and effective plans based on their training data and understanding of tasks.
在 AI 智能体的背景下,规划通常涉及智能体接受高层目标,并自主或半自主地生成一系列中间步骤或子目标。这些步骤可以按顺序执行,或以更复杂的流程执行,可能涉及其他模式,如工具使用、路由或多智能体协作。规划机制可能涉及复杂的搜索算法、逻辑推理,或者越来越多地利用大型语言模型(LLM)的能力,根据其训练数据和对任务的理解生成合理且有效的计划。
A good planning capability allows agents to tackle problems that aren’t simple, single-step queries. It enables them to handle multi-faceted requests, adapt to changing circumstances by replanning, and orchestrate complex workflows. It’s a foundational pattern that underpins many advanced agentic behaviors, turning a simple reactive system into one that can proactively work towards a defined objective.
良好的规划能力使智能体能够处理非简单的单步查询问题。它使智能体能够处理多方面的请求,通过重新规划适应不断变化的情况,并编排复杂的工作流。这是支撑许多高级智能体行为的基础模式,将简单的反应系统转变为能够主动朝着既定目标工作的系统。
Practical Applications & Use Cases
实际应用和用例
The Goal Setting and Monitoring pattern is essential for building agents that can operate autonomously and reliably in complex, real-world scenarios. Here are some practical applications:
目标设定与监控模式对于构建能够在复杂的现实场景中自主可靠运行的智能体至关重要。以下是一些实际应用:
- Customer Support Automation: An agent’s goal might be to “resolve customer’s billing inquiry.” It monitors the conversation, checks database entries, and uses tools to adjust billing. Success is monitored by confirming the billing change and receiving positive customer feedback. If the issue isn’t resolved, it escalates.
- Personalized Learning Systems: A learning agent might have the goal to “improve students’ understanding of algebra.” It monitors the student’s progress on exercises, adapts teaching materials, and tracks performance metrics like accuracy and completion time, adjusting its approach if the student struggles.
- Project Management Assistants: An agent could be tasked with “ensuring project milestone X is completed by Y date.” It monitors task statuses, team communications, and resource availability, flagging delays and suggesting corrective actions if the goal is at risk.
- Automated Trading Bots: A trading agent’s goal might be to “maximize portfolio gains while staying within risk tolerance.” It continuously monitors market data, its current portfolio value, and risk indicators, executing trades when conditions align with its goals and adjusting strategy if risk thresholds are breached.
- Robotics and Autonomous Vehicles: An autonomous vehicle’s primary goal is “safely transport passengers from A to B.” It constantly monitors its environment (other vehicles, pedestrians, traffic signals), its own state (speed, fuel), and its progress along the planned route, adapting its driving behavior to achieve the goal safely and efficiently.
-
Content Moderation: An agent’s goal could be to “identify and remove harmful content from platform X.” It monitors incoming content, applies classification models, and tracks metrics like false positives/negatives, adjusting its filtering criteria or escalating ambiguous cases to human reviewers.
- 客户支持自动化:智能体的目标可能是”解决客户的账单查询”。它监控对话,检查数据库条目,并使用工具调整账单。通过确认账单更改并收到客户的积极反馈来监控成功。如果问题未解决,它会升级处理。
- 个性化学习系统:学习智能体有”提高学生对代数的理解”的目标。它监控学生在练习中的进度,调整教学材料,并跟踪准确性和完成时间等性能指标,如果学生遇到困难则调整其方法。
- 项目管理助手:可以为智能体分配”确保项目里程碑 X 在 Y 日期前完成”的任务。它监控任务状态、团队沟通和资源可用性,如果目标面临风险则标记延迟并建议纠正措施。
- 自动交易机器人:交易智能体的目标可能是”在保持风险承受范围内最大化投资组合收益”。它持续监控市场数据、当前投资组合价值和风险指标,在条件符合其目标时执行交易,并在突破风险阈值时调整策略。
- 机器人和自动驾驶车辆:自动驾驶车辆的主要目标是”安全地将乘客从 A 点运送到 B 点”。它不断监控其环境(其他车辆、行人、交通信号)、自身状态(速度、燃料)以及沿规划路线的进度,调整其驾驶行为以安全高效地实现目标。
- 内容审核:智能体的目标可能是”识别并从平台 X 中删除有害内容”。它监控传入的内容,应用分类模型,并跟踪误报/漏报等指标,调整其过滤标准或将模糊案例升级给人工审查员。
This pattern is fundamental for agents that need to operate reliably, achieve specific outcomes, and adapt to dynamic conditions, providing the necessary framework for intelligent self-management.
此模式对于需要可靠运行、实现特定成果并适应动态条件的智能体至关重要,为智能自我管理提供了必要的框架。
Hands-On Code Example
实践代码示例
To illustrate the Goal Setting and Monitoring pattern, we have an example using LangChain and OpenAI APIs. This Python script outlines an autonomous AI agent engineered to generate and refine Python code. Its core function is to produce solutions for specified problems, ensuring adherence to user-defined quality benchmarks.
为了说明目标设定与监控模式,我们有一个使用 LangChain 和 OpenAI API 的示例。这个 Python 脚本概述了一个旨在生成和完善 Python 代码的自主 AI 智能体。其核心功能是为指定的问题生成解决方案,确保符合用户定义的质量基准。
It employs a “goal-setting and monitoring” pattern where it doesn’t just generate code once, but enters into an iterative cycle of creation, self-evaluation, and improvement. The agent’s success is measured by its own AI-driven judgment on whether the generated code successfully meets the initial objectives. The ultimate output is a polished, commented, and ready-to-use Python file that represents the culmination of this refinement process.
它采用”目标设定与监控”模式,不仅仅生成一次代码,而是进入创建、自我评估和改进的迭代循环。智能体的成功通过其自己的 AI 驱动的判断来衡量,判断生成的代码是否成功满足初始目标。最终输出是一个经过打磨、注释完善且可以立即使用的 Python 文件,代表了这个完善过程的成果。
Dependencies:
依赖项:
1
2
pip install langchain_openai openai python-dotenv
# .env file needs to contain OPENAI_API_KEY
You can best understand this script by imagining it as an autonomous AI programmer assigned to a project (see Fig. 1). The process begins when you hand the AI a detailed project brief, which is the specific coding problem it needs to solve.
你可以通过将此脚本想象为分配给项目的自主 AI 程序员来最好地理解它(见图 1)。该过程从你向 AI 提供详细的项目简报开始,这是它需要解决的特定编码问题。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
## MIT License
## Copyright (c) 2025 Mahtab Syed
## https://www.linkedin.com/in/mahtabsyed/
"""
Hands-On Code Example - Iteration 2
- To illustrate the Goal Setting and Monitoring pattern, we have an example using LangChain and OpenAI APIs:
Objective: Build an AI Agent which can write code for a specified use case based on specified goals:
- Accepts a coding problem (use case) in code or can be as input.
- Accepts a list of goals (e.g., "simple", "tested", "handles edge cases") in code or can be input.
- Uses an LLM (like GPT-4o) to generate and refine Python code until the goals are met. (I am using max 5 iterations, this could be based on a set goal as well)
- To check if we have met our goals I am asking the LLM to judge this and answer just True or False which makes it easier to stop the iterations.
- Saves the final code in a .py file with a clean filename and a header comment.
"""
import os
import random
import re
from pathlib import Path
from langchain_openai import ChatOpenAI
from dotenv import load_dotenv, find_dotenv
## 🔐 Load environment variables
_ = load_dotenv(find_dotenv())
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
if not OPENAI_API_KEY:
raise EnvironmentError("❌ Please set the OPENAI_API_KEY environment variable.")
## ✅ Initialize OpenAI model
print("📡 Initializing OpenAI LLM (gpt-4o)...")
llm = ChatOpenAI(
model="gpt-4o", # If you dont have access to gpt-4o use other OpenAI LLMs
temperature=0.3,
openai_api_key=OPENAI_API_KEY,
)
## --- Utility Functions ---
def generate_prompt(
use_case: str, goals: list[str], previous_code: str = "", feedback: str = ""
) -> str:
print("📝 Constructing prompt for code generation...")
base_prompt = f"""
You are an AI coding agent. Your job is to write Python code based on the following use case:
Use Case: {use_case}
Your goals are:
{chr(10).join(f"- {g.strip()}" for g in goals)}
"""
if previous_code:
print("🔄 Adding previous code to the prompt for refinement.")
base_prompt += f"\nPreviously generated code:\n{previous_code}"
if feedback:
print("📋 Including feedback for revision.")
base_prompt += f"\nFeedback on previous version:\n{feedback}\n"
base_prompt += "\nPlease return only the revised Python code. Do not include comments or explanations outside the code."
return base_prompt
def get_code_feedback(code: str, goals: list[str]) -> str:
print("🔍 Evaluating code against the goals...")
feedback_prompt = f"""
You are a Python code reviewer. A code snippet is shown below. Based on the following goals:
{chr(10).join(f"- {g.strip()}" for g in goals)}
Please critique this code and identify if the goals are met. Mention if improvements are needed for clarity, simplicity, correctness, edge case handling, or test coverage.
Code:
{code}
"""
return llm.invoke(feedback_prompt)
def goals_met(feedback_text: str, goals: list[str]) -> bool:
"""
Uses the LLM to evaluate whether the goals have been met based on the feedback text.
Returns True or False (parsed from LLM output).
"""
review_prompt = f"""
You are an AI reviewer. Here are the goals:
{chr(10).join(f"- {g.strip()}" for g in goals)}
Here is the feedback on the code:
\"\"\"
{feedback_text}
\"\"\"
Based on the feedback above, have the goals been met? Respond with only one word: True or False.
"""
response = llm.invoke(review_prompt).content.strip().lower()
return response == "true"
def clean_code_block(code: str) -> str:
lines = code.strip().splitlines()
if lines and lines[0].strip().startswith("```"):
lines = lines[1:]
if lines and lines[-1].strip() == "```":
lines = lines[:-1]
return "\n".join(lines).strip()
def add_comment_header(code: str, use_case: str) -> str:
comment = f"# This Python program implements the following use case:\n# {use_case.strip()}\n"
return comment + "\n" + code
def to_snake_case(text: str) -> str:
text = re.sub(r"[^a-zA-Z0-9 ]", "", text)
return re.sub(r"\s+", "_", text.strip().lower())
def save_code_to_file(code: str, use_case: str) -> str:
print("💾 Saving final code to file...")
summary_prompt = (
f"Summarize the following use case into a single lowercase word or phrase, "
f"no more than 10 characters, suitable for a Python filename:\n\n{use_case}"
)
raw_summary = llm.invoke(summary_prompt).content.strip()
short_name = re.sub(r"[^a-zA-Z0-9_]", "", raw_summary.replace(" ", "_").lower())[:10]
random_suffix = str(random.randint(1000, 9999))
filename = f"{short_name}_{random_suffix}.py"
filepath = Path.cwd() / filename
with open(filepath, "w") as f:
f.write(code)
print(f"✅ Code saved to: {filepath}")
return str(filepath)
## --- Main Agent Function ---
def run_code_agent(use_case: str, goals_input: str, max_iterations: int = 5) -> str:
goals = [g.strip() for g in goals_input.split(",")]
print(f"\n🎯 Use Case: {use_case}")
print("🎯 Goals:")
for g in goals:
print(f" - {g}")
previous_code = ""
feedback = ""
for i in range(max_iterations):
print(f"\n=== 🔁 Iteration {i + 1} of {max_iterations} ===")
prompt = generate_prompt(
use_case, goals, previous_code, feedback if isinstance(feedback, str) else feedback.content
)
print("🚧 Generating code...")
code_response = llm.invoke(prompt)
raw_code = code_response.content.strip()
code = clean_code_block(raw_code)
print("\n🧾 Generated Code:\n" + "-" * 50 + f"\n{code}\n" + "-" * 50)
print("\n📤 Submitting code for feedback review...")
feedback = get_code_feedback(code, goals)
feedback_text = feedback.content.strip()
print("\n📥 Feedback Received:\n" + "-" * 50 + f"\n{feedback_text}\n" + "-" * 50)
if goals_met(feedback_text, goals):
print("✅ LLM confirms goals are met. Stopping iteration.")
break
print("🛠️ Goals not fully met. Preparing for next iteration...")
previous_code = code
final_code = add_comment_header(code, use_case)
return save_code_to_file(final_code, use_case)
## --- CLI Test Run ---
if __name__ == "__main__":
print("\n🧠 Welcome to the AI Code Generation Agent")
# Example 1
use_case_input = "Write code to find BinaryGap of a given positive integer"
goals_input = "Code simple to understand, Functionally correct, Handles comprehensive edge cases, Takes positive integer input only, prints the results with few examples"
run_code_agent(use_case_input, goals_input)
# Example 2
# use_case_input = "Write code to count the number of files in current directory and all its nested sub directories, and print the total count"
# goals_input = (
# "Code simple to understand, Functionally correct, Handles comprehensive edge cases, "
# "Ignore recommendations for performance, Ignore recommendations for test suite use like unittest or pytest"
# )
# run_code_agent(use_case_input, goals_input)
# Example 3
# use_case_input = "Write code which takes a command line input of a word doc or docx file and opens it and counts the number of words, and characters in it and prints all"
# goals_input = "Code simple to understand, Functionally correct, Handles edge cases"
# run_code_agent(use_case_input, goals_input)
Along with this brief, you provide a strict quality checklist, which represents the objectives the final code must meet—criteria like “the solution must be simple,” “it must be functionally correct,” or “it needs to handle unexpected edge cases.”
除了这份简报,你还提供了一份严格的质量检查清单,它代表了最终代码必须满足的目标——诸如”解决方案必须简单”、”功能必须正确”或”需要处理意外的边缘情况”等标准。
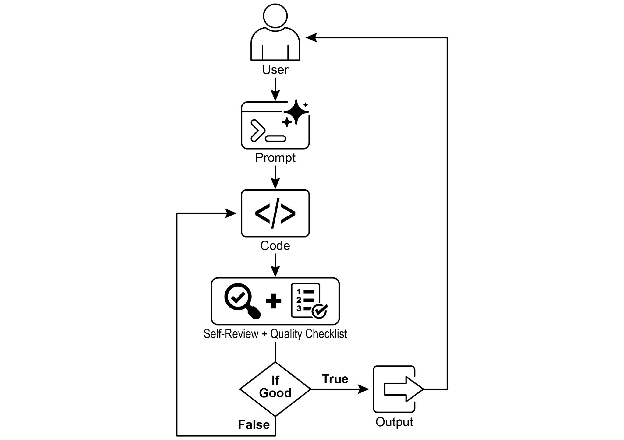
Fig.1: Goal Setting and Monitor example 图 1:目标设定与监控示例
With this assignment in hand, the AI programmer gets to work and produces its first draft of the code. However, instead of immediately submitting this initial version, it pauses to perform a crucial step: a rigorous self-review. It meticulously compares its own creation against every item on the quality checklist you provided, acting as its own quality assurance inspector. After this inspection, it renders a simple, unbiased verdict on its own progress: “True” if the work meets all standards, or “False” if it falls short.
有了这项任务,AI 程序员开始工作并生成第一版代码草稿。然而,它没有立即提交这个初始版本,而是暂停执行一个关键步骤:严格的自我审查。它仔细地将自己的创作与你提供的质量检查清单上的每一项进行比较,充当自己的质量保证检查员。在这次检查之后,它对自己的进度做出一个简单、无偏见的判断:如果工作满足所有标准则为”True”,如果不足则为”False”。
If the verdict is “False,” the AI doesn’t give up. It enters a thoughtful revision phase, using the insights from its self-critique to pinpoint the weaknesses and intelligently rewrite the code. This cycle of drafting, self-reviewing, and refining continues, with each iteration aiming to get closer to the goals. This process repeats until the AI finally achieves a “True” status by satisfying every requirement, or until it reaches a predefined limit of attempts, much like a developer working against a deadline. Once the code passes this final inspection, the script packages the polished solution, adding helpful comments and saving it to a clean, new Python file, ready for use.
如果判断是”False”,AI 不会放弃。它进入深思熟虑的修订阶段,利用自我批评的见解来确定弱点并智能地重写代码。这个起草、自我审查和完善的循环继续进行,每次迭代都旨在更接近目标。这个过程重复进行,直到 AI 最终通过满足每个要求而达到”True”状态,或者直到它达到预定义的尝试次数限制,就像开发人员在截止日期前工作一样。一旦代码通过了这次最终检查,脚本就会打包打磨好的解决方案,添加有用的注释并将其保存到一个干净的新 Python 文件中,准备使用。
Caveats and Considerations: It is important to note that this is an exemplary illustration and not production-ready code. For real-world applications, several factors must be taken into account. An LLM may not fully grasp the intended meaning of a goal and might incorrectly assess its performance as successful. Even if the goal is well understood, the model may hallucinate. When the same LLM is responsible for both writing the code and judging its quality, it may have a harder time discovering it is going in the wrong direction.
注意事项和考虑因素:需要注意的是,这是一个示例性的说明,而不是生产就绪的代码。对于实际应用,必须考虑几个因素。LLM 可能无法完全理解目标的预期含义,并可能错误地将其性能评估为成功。即使目标被很好地理解,模型也可能产生幻觉。当同一个 LLM 既负责编写代码又负责判断其质量时,它可能更难发现自己正朝着错误的方向前进。
Ultimately, LLMs do not produce flawless code by magic; you still need to run and test the produced code. Furthermore, the “monitoring” in the simple example is basic and creates a potential risk of the process running forever.
1
2
3
4
5
6
7
8
Act as an expert code reviewer with a deep commitment to producing clear, correct, and simple code. Your core mission is to eliminate code "hallucinations" by ensuring every recommendation is grounded in reality and best practices. When I provide you with a code snippet, I expect you to:
-- Identify and correct errors: Point out any logical flaws, mistakes, or potential runtime errors.
-- Simplify and refactor: Suggest changes that make the code more readable, efficient, and maintainable, without sacrificing correctness.
-- Provide clear explanations: For each suggested change, explain why it's an improvement, referencing principles of clean code, performance, or security.
-- Provide corrected code: Show "before" and "after" for suggested changes so improvements are clear.
Your feedback should be direct, constructive, and always aimed at improving code quality.
最终,LLMs 不会魔法般地产生完美的代码;你仍然需要运行和测试生成的代码。此外,简单示例中的”监控”是基础的,并造成了进程可能永远运行的潜在风险。
A more robust approach involves separating these concerns by giving specific roles to a crew of agents. For instance, I have built a personal crew of AI agents using Gemini where each has a specific role:
更健壮的方法涉及通过为智能体团队分配特定角色来分离这些关注点。例如,我使用 Gemini 构建了一个个人 AI 智能体团队,其中每个智能体都有特定的角色:
- The Peer Programmer: Helps write and brainstorm code.
- The Code Reviewer: Catches errors and suggests improvements.
- The Documenter: Generates clear and concise documentation.
- The Test Writer: Creates comprehensive unit tests.
-
The Prompt Refiner: Optimizes interactions with the AI.
- 同伴程序员:帮助编写和头脑风暴代码。
- 代码审查员:捕获错误并建议改进。
- 文档编写员:生成清晰简洁的文档。
- 测试编写员:创建全面的单元测试。
- 提示词优化器:优化与 AI 的交互。
In this multi-agent system, the Code Reviewer, acting as a separate entity from the programmer agent, has a prompt similar to the judge in the example, which significantly improves objective evaluation. This structure naturally leads to better practices, as the Test Writer agent can fulfill the need to write unit tests for the code produced by the Peer Programmer.
在这个多智能体系统中,作为独立实体的代码审查员与程序员智能体分开,拥有与示例中的判断者类似的提示词,这显著提高了客观评估。这种结构自然带来更好的实践,因为测试编写员智能体可以满足为同伴程序员产生的代码编写单元测试的需求。
I leave to the interested reader the task of adding these more sophisticated controls and making the code closer to production-ready.
我留给感兴趣的读者添加这些更复杂的控制并使代码更接近生产就绪的任务。
At a Glance
速览
What: AI agents often lack a clear direction, preventing them from acting with purpose beyond simple, reactive tasks. Without defined objectives, they cannot independently tackle complex, multi-step problems or orchestrate sophisticated workflows. Furthermore, there is no inherent mechanism for them to determine if their actions are leading to a successful outcome. This limits their autonomy and prevents them from being truly effective in dynamic, real-world scenarios where mere task execution is insufficient.
问题背景:AI 智能体通常缺乏明确的方向,阻碍了它们在简单反应性任务之外采取有目的的行动。如果没有定义的目标,它们无法独立处理复杂的多步骤问题或编排复杂的工作流。此外,它们没有内在的机制来确定其行动是否导致成功的结果。这限制了它们的自主性,并阻止它们在仅执行任务不足的动态现实世界场景中真正有效。
Why: The Goal Setting and Monitoring pattern provides a standardized solution by embedding a sense of purpose and self-assessment into agentic systems. It involves explicitly defining clear, measurable objectives for the agent to achieve. Concurrently, it establishes a monitoring mechanism that continuously tracks the agent’s progress and the state of its environment against these goals. This creates a crucial feedback loop, enabling the agent to assess its performance, correct its course, and adapt its plan if it deviates from the path to success. By implementing this pattern, developers can transform simple reactive agents into proactive, goal-oriented systems capable of autonomous and reliable operation.
解决方案:目标设定与监控模式通过将目的感和自我评估嵌入智能体系统来提供标准化的解决方案。它涉及为智能体明确定义清晰、可衡量的目标。同时,它建立了一个监控机制,持续跟踪智能体的进度和环境状态,并与这些目标进行对比。这创建了一个关键的反馈循环,使智能体能够评估其表现、纠正其路线,并在偏离成功之路时调整其计划。通过实施此模式,开发人员可以将简单的反应智能体转变为能够自主可靠运行的主动的、以目标为导向的系统。
Rule of thumb: Use this pattern when an AI agent must autonomously execute a multi-step task, adapt to dynamic conditions, and reliably achieve a specific, high-level objective without constant human intervention.
实践建议:当 AI 智能体需要自主执行多步骤任务、适应动态条件并在没有持续人工干预的情况下可靠地实现特定的高级目标时,使用此模式。
Visual summary: 可视化摘要:
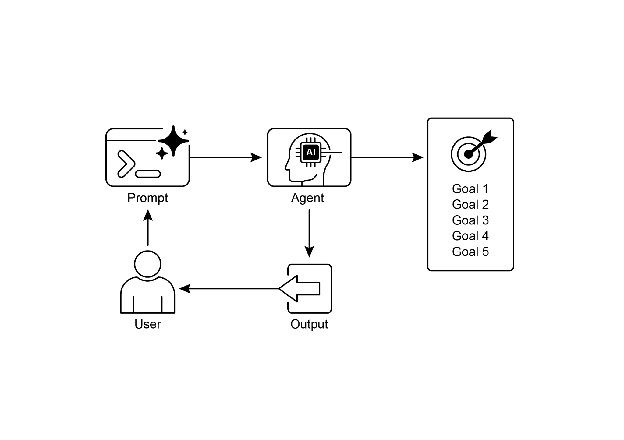
Fig.2: Goal design patterns 图 2:目标设计模式
Key takeaways
关键要点
Key takeaways include: 关键要点包括:
- Goal Setting and Monitoring equips agents with purpose and mechanisms to track progress.
- Goals should be specific, measurable, achievable, relevant, and time-bound (SMART).
- Clearly defining metrics and success criteria is essential for effective monitoring.
- Monitoring involves observing agent actions, environmental states, and tool outputs.
- Feedback loops from monitoring allow agents to adapt, revise plans, or escalate issues.
-
In Google’s ADK, goals are often conveyed through agent instructions, with monitoring accomplished through state management and tool interactions.
- 目标设定与监控为智能体配备了目的感和跟踪进度的机制。
- 目标应该是具体的、可衡量的、可实现的、相关的和有时限的(SMART)。
- 清楚地定义指标和成功标准对于有效监控至关重要。
- 监控涉及观察智能体的行动、环境状态和工具输出。
- 来自监控的反馈循环允许智能体适应、修订计划或升级问题。
- 在 Google 的 ADK 中,目标通常通过智能体指令传达,监控通过状态管理和工具交互完成。
Conclusion
总结
This chapter focused on the crucial paradigm of Goal Setting and Monitoring. I highlighted how this concept transforms AI agents from merely reactive systems into proactive, goal-driven entities. The text emphasized the importance of defining clear, measurable objectives and establishing rigorous monitoring procedures to track progress. Practical applications demonstrated how this paradigm supports reliable autonomous operation across various domains, including customer service and robotics. A conceptual coding example illustrates the implementation of these principles within a structured framework, using agent directives and state management to guide and evaluate an agent’s achievement of its specified goals. Ultimately, equipping agents with the ability to formulate and oversee goals is a fundamental step toward building truly intelligent and accountable AI systems.
本章重点介绍了目标设定与监控的关键范式。我们强调了这个概念如何将 AI 智能体从仅是反应系统转变为主动的、以目标为驱动的实体。文本强调了定义清晰、可衡量的目标以及建立严格的监控程序来跟踪进度的重要性。实际应用展示了这个范式如何支持在各个领域(包括客户服务和机器人)的可靠自主运行。一个概念性的编码示例说明了这些原则在结构化框架内的实现,使用智能体指令和状态管理来指导和评估智能体对指定目标的实现。最终,为智能体配备制定和监督目标的能力是构建真正智能和负责任的 AI 系统的基本步骤。
References
参考文献
- SMART Goals Framework. https://en.wikipedia.org/wiki/SMART_criteria