Chapter 21: Exploration and Discovery
第 21 章:探索和发现
This chapter explores patterns that enable intelligent agents to actively seek out novel information, uncover new possibilities, and identify unknown unknowns within their operational environment. Exploration and discovery differ from reactive behaviors or optimization within a predefined solution space. Instead, they focus on agents proactively venturing into unfamiliar territories, experimenting with new approaches, and generating new knowledge or understanding. This pattern is crucial for agents operating in open-ended, complex, or rapidly evolving domains where static knowledge or pre-programmed solutions are insufficient. It emphasizes the agent’s capacity to expand its understanding and capabilities.
本章探讨了使智能体能够主动寻求新信息、发现新可能性并识别其操作环境中未知因素的模式。探索和发现不同于被动行为或在预定义解决方案空间内的优化。相反,它们侧重于智能体主动进入陌生领域、尝试新方法并生成新知识或理解。这种模式对于在开放式、复杂或快速演变的领域中运行的智能体至关重要,在这些领域中,静态知识或预编程的解决方案是不够的。它强调智能体扩展其理解和能力的能力。
Practical Applications & Use Cases
实际应用和用例
AI agents possess the ability to intelligently prioritize and explore, which leads to applications across various domains. By autonomously evaluating and ordering potential actions, these agents can navigate complex environments, uncover hidden insights, and drive innovation. This capacity for prioritized exploration enables them to optimize processes, discover new knowledge, and generate content.
AI 智能体拥有智能优先级排序和探索的能力,这使其能在各个领域得到广泛应用。通过自主评估和排序潜在行动,这些智能体可以在复杂环境中导航、发现隐藏的洞察并推动创新。这种优先探索的能力使它们能够优化流程、发现新知识并生成内容。
Examples:
示例:
- Scientific Research Automation: An agent designs and runs experiments, analyzes results, and formulates new hypotheses to discover novel materials, drug candidates, or scientific principles.
- Game Playing and Strategy Generation: Agents explore game states, discovering emergent strategies or identifying vulnerabilities in game environments (e.g., AlphaGo).
- Market Research and Trend Spotting: Agents scan unstructured data (social media, news, reports) to identify trends, consumer behaviors, or market opportunities.
- Security Vulnerability Discovery: Agents probe systems or codebases to find security flaws or attack vectors.
- Creative Content Generation: Agents explore combinations of styles, themes, or data to generate artistic pieces, musical compositions, or literary works.
-
Personalized Education and Training: AI tutors prioritize learning paths and content delivery based on a student’s progress, learning style, and areas needing improvement.
- 科学研究自动化:智能体设计和运行实验、分析结果并制定新假设,以发现新材料、候选药物或科学原理。
- 游戏玩法和策略生成:智能体探索游戏状态,发现新兴策略或识别游戏环境中的漏洞(例如 AlphaGo)。
- 市场研究和趋势发现:智能体扫描非结构化数据(社交媒体、新闻、报告)以识别趋势、消费者行为或市场机会。
- 安全漏洞发现:智能体探测系统或代码库以查找安全漏洞或攻击向量。
- 创意内容生成:智能体探索风格、主题或数据的组合,以生成艺术作品、音乐作品或文学作品。
- 个性化教育和培训:AI 导师根据学生的进度、学习风格和需要改进的领域来优先处理学习路径和内容交付。
Google Co-Scientist
Google 协同科学家(Google Co-Scientist)
An AI co-scientist is an AI system developed by Google Research designed as a computational scientific collaborator. It assists human scientists in research aspects such as hypothesis generation, proposal refinement, and experimental design. This system operates on the Gemini LLM..
AI 协同科学家是由 Google Research 开发的 AI 系统,被设计为计算科学合作者。它在假设生成、提案改进和实验设计等研究方面协助人类科学家。该系统基于 Gemini 大语言模型运行。
The development of the AI co-scientist addresses challenges in scientific research. These include processing large volumes of information, generating testable hypotheses, and managing experimental planning. The AI co-scientist supports researchers by performing tasks that involve large-scale information processing and synthesis, potentially revealing relationships within data. Its purpose is to augment human cognitive processes by handling computationally demanding aspects of early-stage research.
AI 协同科学家的开发旨在解决科学研究中的挑战。这些挑战包括处理大量信息、生成可检验的假设以及管理实验规划。AI 协同科学家通过执行涉及大规模信息处理和综合的任务来支持研究人员,可能揭示数据中的关系。其目标是通过处理早期研究中计算密集型的方面来增强人类认知过程。
System Architecture and Methodology: The architecture of the AI co-scientist is based on a multi-agent framework, structured to emulate collaborative and iterative processes. This design integrates specialized AI agents, each with a specific role in contributing to a research objective. A supervisor agent manages and coordinates the activities of these individual agents within an asynchronous task execution framework that allows for flexible scaling of computational resources.
系统架构和方法论: AI 协同科学家的架构基于多智能体框架,结构化以模拟协作和迭代过程。这种设计集成了专门的 AI 智能体,每个智能体在为研究目标做出贡献方面都有特定的角色。一个主管智能体在异步任务执行框架内管理和协调这些单独智能体的活动,该框架允许计算资源的灵活扩展。
The core agents and their functions include (see Fig. 1):
核心智能体功能包括(见图 1):
- Generation agent: Initiates the process by producing initial hypotheses through literature exploration and simulated scientific debates.
- Reflection agent: Acts as a peer reviewer, critically assessing the correctness, novelty, and quality of the generated hypotheses.
- Ranking agent: Employs an Elo-based tournament to compare, rank, and prioritize hypotheses through simulated scientific debates.
- Evolution agent: Continuously refines top-ranked hypotheses by simplifying concepts, synthesizing ideas, and exploring unconventional reasoning.
- Proximity agent: Computes a proximity graph to cluster similar ideas and assist in exploring the hypothesis landscape.
-
Meta-review agent: Synthesizes insights from all reviews and debates to identify common patterns and provide feedback, enabling the system to continuously improve.
- 生成智能体:通过文献探索和模拟科学辩论来生成初始假设,从而启动流程。
- 反思智能体:作为同行评审员,批判性地评估生成假设的正确性、新颖性和质量。
- 排名智能体:采用基于 Elo 的锦标赛机制,通过模拟科学辩论来比较、排名和优先处理假设。
- 进化智能体:通过简化概念、综合想法和探索非常规推理,不断完善排名靠前的假设。
- 邻近度智能体:计算邻近度图以聚类相似想法并协助探索假设格局。
- 元审查智能体:综合所有审查和辩论的见解,以识别共同模式并提供反馈,使系统能够持续改进。
The system’s operational foundation relies on Gemini, which provides language understanding, reasoning, and generative abilities. The system incorporates “test-time compute scaling,” a mechanism that allocates increased computational resources to iteratively reason and enhance outputs. The system processes and synthesizes information from diverse sources, including academic literature, web-based data, and databases.
该系统的运营基础依赖于 Gemini,它提供语言理解、推理和生成能力。该系统包含”测试时计算扩展”机制,通过分配增加的计算资源来迭代推理和增强输出。该系统处理和综合来自不同来源的信息,包括学术文献、基于网络的数据和数据库。
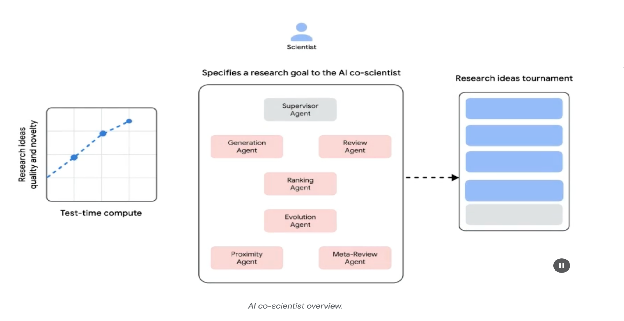
Fig. 1: (Courtesy of the Authors) AI Co-Scientist: Ideation to Validation
图 1:(由作者提供)AI 协同科学家:从构思到验证
The system follows an iterative “generate, debate, and evolve” approach mirroring the scientific method. Following the input of a scientific problem from a human scientist, the system engages in a self-improving cycle of hypothesis generation, evaluation, and refinement. Hypotheses undergo systematic assessment, including internal evaluations among agents and a tournament-based ranking mechanism.
该系统遵循反映科学方法的迭代”生成、辩论和进化”方法。在从人类科学家那里接收科学问题的输入后,系统参与假设生成、评估和改进的自我改进循环。假设经过系统评估,包括智能体之间的内部评估和基于锦标赛的排名机制。
Validation and Results: The AI co-scientist’s utility has been demonstrated in several validation studies, particularly in biomedicine, assessing its performance through automated benchmarks, expert reviews, and end-to-end wet-lab experiments.
验证和结果: AI 协同科学家的效用已在几项验证研究中得到证明,特别是在生物医学领域,通过自动化基准、专家评审和端到端湿实验室实验来评估其性能。
Automated and Expert Evaluation: On the challenging GPQA benchmark, the system’s internal Elo rating was shown to be concordant with the accuracy of its results, achieving a top-1 accuracy of 78.4% on the difficult “diamond set”. Analysis across over 200 research goals demonstrated that scaling test-time compute consistently improves the quality of hypotheses, as measured by the Elo rating. On a curated set of 15 challenging problems, the AI co-scientist outperformed other state-of-the-art AI models and the “best guess” solutions provided by human experts. In a small-scale evaluation, biomedical experts rated the co-scientist’s outputs as more novel and impactful compared to other baseline models. The system’s proposals for drug repurposing, formatted as NIH Specific Aims pages, were also judged to be of high quality by a panel of six expert oncologists.
自动化和专家评估: 在具有挑战性的 GPQA 基准上,该系统的内部 Elo 评级被证明与其结果的准确性一致,在困难的”钻石集”上实现了 78.4% 的 top-1 准确率。对超过 200 个研究目标的分析表明,扩展测试时计算可持续提高假设的质量,通过 Elo 评级来衡量。在精心策划的 15 个挑战性问题集上,AI 协同科学家的表现优于其他最先进的 AI 模型和人类专家提供的”最佳猜测”解决方案。在小规模评估中,生物医学专家将协同科学家的输出评为比其他基线模型更新颖、更有影响力。该系统针对药物再利用的提案(格式化为 NIH 特定目标页面)也被六位专家肿瘤学家小组评判为高质量。
End-to-End Experimental Validation:
端到端实验验证:
Drug Repurposing: For acute myeloid leukemia (AML), the system proposed novel drug candidates. Some of these, like KIRA6, were completely novel suggestions with no prior preclinical evidence for use in AML. Subsequent in vitro experiments confirmed that KIRA6 and other suggested drugs inhibited tumor cell viability at clinically relevant concentrations in multiple AML cell lines.
药物再利用:对于急性髓系白血病(AML),该系统提出了新的候选药物。其中一些,如 KIRA6,是完全新颖的建议,之前没有在 AML 中使用的临床前证据。随后的体外实验证实,KIRA6 和其他建议的药物在多个 AML 细胞系中以临床相关浓度抑制肿瘤细胞活力。
Novel Target Discovery: The system identified novel epigenetic targets for liver fibrosis. Laboratory experiments using human hepatic organoids validated these findings, showing that drugs targeting the suggested epigenetic modifiers had significant anti-fibrotic activity. One of the identified drugs is already FDA-approved for another condition, opening an opportunity for repurposing.
新靶点发现:该系统识别了肝纤维化的新表观遗传靶点。使用人类肝脏类器官的实验室实验验证了这些发现,表明针对建议的表观遗传修饰剂的药物具有显著的抗纤维化活性。其中一种已识别的药物已被 FDA 批准用于另一种疾病,为再利用提供了机会。
Antimicrobial Resistance: The AI co-scientist independently recapitulated unpublished experimental findings. It was tasked to explain why certain mobile genetic elements (cf-PICIs) are found across many bacterial species. In two days, the system’s top-ranked hypothesis was that cf-PICIs interact with diverse phage tails to expand their host range. This mirrored the novel, experimentally validated discovery that an independent research group had reached after more than a decade of research.
抗微生物耐药性:AI 协同科学家独立重现了未发表的实验发现。它被要求解释为什么某些移动遗传元件(cf-PICIs)在许多细菌种中被发现。在两天内,该系统排名最高的假设是 cf-PICIs 与不同的噬菌体尾部相互作用以扩展其宿主范围。这反映了一个独立研究小组在十多年的研究后达到的新颖的、经实验验证的发现。
Augmentation, and Limitations: The design philosophy behind the AI co-scientist emphasizes augmentation rather than complete automation of human research. Researchers interact with and guide the system through natural language, providing feedback, contributing their own ideas, and directing the AI’s exploratory processes in a “scientist-in-the-loop” collaborative paradigm. However, the system has some limitations. Its knowledge is constrained by its reliance on open-access literature, potentially missing critical prior work behind paywalls. It also has limited access to negative experimental results, which are rarely published but crucial for experienced scientists. Furthermore, the system inherits limitations from the underlying LLMs, including the potential for factual inaccuracies or “hallucinations”.
增强与局限性: AI 协同科学家背后的设计理念强调增强而不是完全自动化人类研究。研究人员通过自然语言与系统交互并指导系统,提供反馈、贡献自己的想法,并在”科学家在环”的协作范式中指导 AI 的探索过程。然而,该系统有一些局限性。其知识受到对开放获取文献的依赖的限制,可能会遗漏付费墙后的关键先前工作。它对负面实验结果的访问也有限,这些结果很少发表,但对经验丰富的科学家至关重要。此外,该系统继承了底层大语言模型的局限性,包括事实不准确或”幻觉”的潜力。
Safety: Safety is a critical consideration, and the system incorporates multiple safeguards. All research goals are reviewed for safety upon input, and generated hypotheses are also checked to prevent the system from being used for unsafe or unethical research. A preliminary safety evaluation using 1,200 adversarial research goals found that the system could robustly reject dangerous inputs. To ensure responsible development, the system is being made available to more scientists through a Trusted Tester Program to gather real-world feedback.
安全性: 安全性是一个关键考虑因素,系统包含多个保障措施。所有研究目标在输入时都会进行安全审查,生成的假设也会被检查,以防止系统被用于不安全或不道德的研究。使用 1,200 个对抗性研究目标进行的初步安全评估发现,该系统可以稳健地拒绝危险输入。为确保负责任的开发,该系统正通过可信测试者计划向更多科学家提供,以收集实际反馈。
Hands-On Code Example
实践代码示例
Let’s look at a concrete example of agentic AI for Exploration and Discovery in action: Agent Laboratory, a project developed by Samuel Schmidgall under the MIT License.
让我们看一个探索和发现中智能体 AI 的具体示例:Agent Laboratory,这是 Samuel Schmidgall 在 MIT 许可下开发的项目。
“Agent Laboratory” is an autonomous research workflow framework designed to augment human scientific endeavors rather than replace them. This system leverages specialized LLMs to automate various stages of the scientific research process, thereby enabling human researchers to dedicate more cognitive resources to conceptualization and critical analysis.
“Agent Laboratory”是一个自主研究工作流框架,旨在增强而不是取代人类科学努力。该系统利用专门的大语言模型来自动化科学研究过程的各个阶段,从而使人类研究人员能够将更多认知资源用于概念化和批判性分析。
The framework integrates “AgentRxiv,” a decentralized repository for autonomous research agents. AgentRxiv facilitates the deposition, retrieval, and development of research outputs
该框架集成了”AgentRxiv”,这是一个用于自主研究智能体的去中心化存储库。AgentRxiv 促进研究输出的存储、检索和开发。
Agent Laboratory guides the research process through distinct phases:
Agent Laboratory 通过不同的阶段指导研究过程:
- Literature Review: During this initial phase, specialized LLM-driven agents are tasked with the autonomous collection and critical analysis of pertinent scholarly literature. This involves leveraging external databases such as arXiv to identify, synthesize, and categorize relevant research, effectively establishing a comprehensive knowledge base for the subsequent stages.
- Experimentation: This phase encompasses the collaborative formulation of experimental designs, data preparation, execution of experiments, and analysis of results. Agents utilize integrated tools like Python for code generation and execution, and Hugging Face for model access, to conduct automated experimentation. The system is designed for iterative refinement, where agents can adapt and optimize experimental procedures based on real-time outcomes.
- Report Writing: In the final phase, the system automates the generation of comprehensive research reports. This involves synthesizing findings from the experimentation phase with insights from the literature review, structuring the document according to academic conventions, and integrating external tools like LaTeX for professional formatting and figure generation.
-
Knowledge Sharing: AgentRxiv is a platform enabling autonomous research agents to share, access, and collaboratively advance scientific discoveries. It allows agents to build upon previous findings, fostering cumulative research progress.
- 文献综述:在这个初始阶段,专门的大语言模型驱动的智能体自主收集和批判性分析相关学术文献。这涉及利用 arXiv 等外部数据库来识别、综合和分类相关研究,有效地为后续阶段建立全面的知识库。
- 实验:此阶段包括实验设计的协作制定、数据准备、实验执行和结果分析。智能体利用集成工具(如用于代码生成和执行的 Python,以及用于模型访问的 Hugging Face)来进行自动化实验。该系统设计用于迭代改进,智能体可以根据实时结果调整和优化实验程序。
- 报告撰写:在最后阶段,系统自动生成全面的研究报告。这涉及将实验阶段的发现与文献综述的见解相结合,根据学术惯例构建文档,并集成外部工具(如用于专业格式化和图形生成的 LaTeX)。
- 知识共享:AgentRxiv 是一个平台,使自主研究智能体能够共享、访问和协作推进科学发现。它允许智能体在先前发现的基础上构建,促进累积的研究进展。
The modular architecture of Agent Laboratory ensures computational flexibility. The aim is to enhance research productivity by automating tasks while maintaining the human researcher.
Agent Laboratory 的模块化架构确保了计算灵活性。其目标是通过自动化任务来提高研究生产力,同时保持人类研究人员的参与。
Code analysis: While a comprehensive code analysis is beyond the scope of this book, I want to provide you with some key insights and encourage you to delve into the code on your own.
代码分析: 虽然全面的代码分析超出了本书的范围,但我想为您提供一些关键见解,并鼓励您自己深入研究代码。
Judgment: In order to emulate human evaluative processes, the system employs a tripartite agentic judgment mechanism for assessing outputs. This involves the deployment of three distinct autonomous agents, each configured to evaluate the production from a specific perspective, thereby collectively mimicking the nuanced and multi-faceted nature of human judgment. This approach allows for a more robust and comprehensive appraisal, moving beyond singular metrics to capture a richer qualitative assessment.
判断: 为了模拟人类评估过程,系统采用三方智能体判断机制来评估输出。这涉及部署三个不同的自主智能体,每个智能体配置为从特定角度评估产出,从而共同模仿人类判断的细致和多方面性质。这种方法允许更稳健和全面的评估,超越单一指标以捕获更丰富的定性评估。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class ReviewersAgent:
def __init__(self, model="gpt-4o-mini", notes=None, openai_api_key=None):
if notes is None:
self.notes = []
else:
self.notes = notes
self.model = model
self.openai_api_key = openai_api_key
def inference(self, plan, report):
reviewer_1 = "You are a harsh but fair reviewer and expect good experiments that lead to insights for the research topic."
review_1 = get_score(outlined_plan=plan, latex=report, reward_model_llm=self.model, reviewer_type=reviewer_1, openai_api_key=self.openai_api_key)
reviewer_2 = "You are a harsh and critical but fair reviewer who is looking for an idea that would be impactful in the field."
review_2 = get_score(outlined_plan=plan, latex=report, reward_model_llm=self.model, reviewer_type=reviewer_2, openai_api_key=self.openai_api_key)
reviewer_3 = "You are a harsh but fair open-minded reviewer that is looking for novel ideas that have not been proposed before."
review_3 = get_score(outlined_plan=plan, latex=report, reward_model_llm=self.model, reviewer_type=reviewer_3, openai_api_key=self.openai_api_key)
return f"Reviewer #1:\n{review_1}, \nReviewer #2:\n{review_2}, \nReviewer #3:\n{review_3}"
The judgment agents are designed with a specific prompt that closely emulates the cognitive framework and evaluation criteria typically employed by human reviewers. This prompt guides the agents to analyze outputs through a lens similar to how a human expert would, considering factors like relevance, coherence, factual accuracy, and overall quality. By crafting these prompts to mirror human review protocols, the system aims to achieve a level of evaluative sophistication that approaches human-like discernment.
判断智能体设计采用了特定的提示词,该提示词密切模拟了人类审稿人通常采用的认知框架和评估标准。此提示词指导智能体以类似于人类专家的方式分析输出,考虑相关性、连贯性、事实准确性和整体质量等因素。通过精心设计这些提示词以反映人类审查协议,该系统旨在实现接近人类判断力的评估复杂性水平。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
def get_score(outlined_plan, latex, reward_model_llm, reviewer_type=None, attempts=3, openai_api_key=None):
e = str()
for _attempt in range(attempts):
try:
template_instructions = """
Respond in the following format:
THOUGHT:
<THOUGHT>
REVIEW JSON:
```json
<JSON>
```
In <THOUGHT>, first briefly discuss your intuitions
and reasoning for the evaluation.
Detail your high-level arguments, necessary choices
and desired outcomes of the review.
Do not make generic comments here, but be specific
to your current paper.
Treat this as the note-taking phase of your review.
In <JSON>, provide the review in JSON format with
the following fields in the order:
- "Summary": A summary of the paper content and
its contributions.
- "Strengths": A list of strengths of the paper.
- "Weaknesses": A list of weaknesses of the paper.
- "Originality": A rating from 1 to 4
(low, medium, high, very high).
- "Quality": A rating from 1 to 4
(low, medium, high, very high).
- "Clarity": A rating from 1 to 4
(low, medium, high, very high).
- "Significance": A rating from 1 to 4
(low, medium, high, very high).
- "Questions": A set of clarifying questions to be
answered by the paper authors.
- "Limitations": A set of limitations and potential
negative societal impacts of the work.
- "Ethical Concerns": A boolean value indicating
whether there are ethical concerns.
- "Soundness": A rating from 1 to 4
(poor, fair, good, excellent).
- "Presentation": A rating from 1 to 4
(poor, fair, good, excellent).
- "Contribution": A rating from 1 to 4
(poor, fair, good, excellent).
- "Overall": A rating from 1 to 10
(very strong reject to award quality).
- "Confidence": A rating from 1 to 5
(low, medium, high, very high, absolute).
- "Decision": A decision that has to be one of the
following: Accept, Reject.
For the "Decision" field, don't use Weak Accept,
Borderline Accept, Borderline Reject, or Strong Reject.
Instead, only use Accept or Reject.
This JSON will be automatically parsed, so ensure
the format is precise.
"""
In this multi-agent system, the research process is structured around specialized roles, mirroring a typical academic hierarchy to streamline workflow and optimize output.
在这个多智能体系统中,研究过程围绕专门角色构建,反映了典型的学术层次结构,以简化工作流程并优化输出。
Professor Agent: The Professor Agent functions as the primary research director, responsible for establishing the research agenda, defining research questions, and delegating tasks to other agents. This agent sets the strategic direction and ensures alignment with project objectives.
教授智能体: 教授智能体作为主要研究主管,负责建立研究议程、定义研究问题并将任务委托给其他智能体。该智能体设定战略方向并确保与项目目标保持一致。
1
2
3
4
5
6
7
8
9
10
11
12
13
class ProfessorAgent(BaseAgent):
def __init__(self, model="gpt4omini", notes=None, max_steps=100, openai_api_key=None):
super().__init__(model, notes, max_steps, openai_api_key)
self.phases = ["report writing"]
def generate_readme(self):
sys_prompt = f"""You are {self.role_description()} \n Here is the written paper \n{self.report}. Task instructions: Your goal is to integrate all of the knowledge, code, reports, and notes provided to you and generate a readme.md for a github repository."""
history_str = "\n".join([_[1] for _ in self.history])
prompt = (
f"""History: {history_str}\n{'~' * 10}\n"""
f"Please produce the readme below in markdown:\n")
model_resp = query_model(model_str=self.model, system_prompt=sys_prompt, prompt=prompt, openai_api_key=self.openai_api_key)
return model_resp.replace("```markdown", "")
PostDoc Agent: The PostDoc Agent’s role is to execute the research. This includes conducting literature reviews, designing and implementing experiments, and generating research outputs such as papers. Importantly, the PostDoc Agent has the capability to write and execute code, enabling the practical implementation of experimental protocols and data analysis. This agent is the primary producer of research artifacts.
博士后智能体: 博士后智能体的角色是执行研究。这包括进行文献综述、设计和实施实验以及生成研究输出(如论文)。重要的是,博士后智能体拥有编写和执行代码的能力,使实验协议和数据分析的实际实施成为可能。该智能体是研究成果的主要生产者。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
class PostdocAgent(BaseAgent):
def __init__(self, model="gpt4omini", notes=None, max_steps=100, openai_api_key=None):
super().__init__(model, notes, max_steps, openai_api_key)
self.phases = ["plan formulation", "results interpretation"]
def context(self, phase):
sr_str = str()
if self.second_round:
sr_str = (
f"The following are results from the previous experiments\n",
f"Previous Experiment code: {self.prev_results_code}\n"
f"Previous Results: {self.prev_exp_results}\n"
f"Previous Interpretation of results: {self.prev_interpretation}\n"
f"Previous Report: {self.prev_report}\n"
f"{self.reviewer_response}\n\n\n"
)
if phase == "plan formulation":
return (
sr_str,
f"Current Literature Review: {self.lit_review_sum}",
)
elif phase == "results interpretation":
return (
sr_str,
f"Current Literature Review: {self.lit_review_sum}\n"
f"Current Plan: {self.plan}\n"
f"Current Dataset code: {self.dataset_code}\n"
f"Current Experiment code: {self.results_code}\n"
f"Current Results: {self.exp_results}"
)
return ""
Reviewer Agents: Reviewer agents perform critical evaluations of research outputs from the PostDoc Agent, assessing the quality, validity, and scientific rigor of papers and experimental results. This evaluation phase emulates the peer-review process in academic settings to ensure a high standard of research output before finalization.
审稿人智能体: 审稿人智能体对博士后智能体的研究输出进行批判性评估,评估论文和实验结果的质量、有效性和科学严谨性。这个评估阶段模拟学术环境中的同行评审过程,以确保在最终确定之前研究输出的高标准。
ML Engineering Agents:The Machine Learning Engineering Agents serve as machine learning engineers, engaging in dialogic collaboration with a PhD student to develop code. Their central function is to generate uncomplicated code for data preprocessing, integrating insights derived from the provided literature review and experimental protocol. This guarantees that the data is appropriately formatted and prepared for the designated experiment.
机器学习工程智能体: 机器学习工程智能体作为机器学习工程师,与博士生进行对话式协作以开发代码。他们的核心功能是为数据预处理生成简单的代码,整合从提供的文献综述和实验协议中得出的见解。这确保数据被适当格式化并为指定的实验做好准备。
1
2
"You are a machine learning engineer being directed by a PhD student who will help you write the code, and you can interact with them through dialogue.\n"
"Your goal is to produce code that prepares the data for the provided experiment. You should aim for simple code to prepare the data, not complex code. You should integrate the provided literature review and the plan and come up with code to prepare data for this experiment.\n"
SWEngineerAgents: Software Engineering Agents guide Machine Learning Engineer Agents. Their main purpose is to assist the Machine Learning Engineer Agent in creating straightforward data preparation code for a specific experiment. The Software Engineer Agent integrates the provided literature review and experimental plan, ensuring the generated code is uncomplicated and directly relevant to the research objectives.
软件工程智能体: 软件工程智能体指导机器学习工程智能体。他们的主要目的是协助机器学习工程智能体为特定实验创建简单的数据准备代码。软件工程智能体整合提供的文献综述和实验计划,确保生成的代码简单明了,并与研究目标直接相关。
1
2
"You are a software engineer directing a machine learning engineer, where the machine learning engineer will be writing the code, and you can interact with them through dialogue.\n"
"Your goal is to help the ML engineer produce code that prepares the data for the provided experiment. You should aim for very simple code to prepare the data, not complex code. You should integrate the provided literature review and the plan and come up with code to prepare data for this experiment.\n"
In summary, “Agent Laboratory” represents a sophisticated framework for autonomous scientific research. It is designed to augment human research capabilities by automating key research stages and facilitating collaborative AI-driven knowledge generation. The system aims to increase research efficiency by managing routine tasks while maintaining human oversight.
总之,”Agent Laboratory”代表了自主科学研究的复杂框架。它旨在通过自动化关键研究阶段和促进 AI 驱动的知识生成来增强人类研究能力。该系统旨在通过管理日常任务来提高研究效率,同时保持人类监督。
At a Glance
速览
What: AI agents often operate within predefined knowledge, limiting their ability to tackle novel situations or open-ended problems. In complex and dynamic environments, this static, pre-programmed information is insufficient for true innovation or discovery. The fundamental challenge is to enable agents to move beyond simple optimization to actively seek out new information and identify “unknown unknowns.” This necessitates a paradigm shift from purely reactive behaviors to proactive, Agentic exploration that expands the system’s own understanding and capabilities.
问题背景:AI 智能体通常在预定义的知识范围内运行,限制了它们处理新情况或开放式问题的能力。在复杂和动态的环境中,这种静态的、预编程的信息不足以实现真正的创新或发现。根本挑战是使智能体超越简单的优化,主动寻求新信息并识别”未知的未知因素”。这需要从纯粹的被动行为转变为扩展系统自身理解和能力的主动智能体探索。
Why: The standardized solution is to build Agentic AI systems specifically designed for autonomous exploration and discovery. These systems often utilize a multi-agent framework where specialized LLMs collaborate to emulate processes like the scientific method. For instance, distinct agents can be tasked with generating hypotheses, critically reviewing them, and evolving the most promising concepts. This structured, collaborative methodology allows the system to intelligently navigate vast information landscapes, design and execute experiments, and generate genuinely new knowledge. By automating the labor-intensive aspects of exploration, these systems augment human intellect and significantly accelerate the pace of discovery.
解决方案:标准化的解决方案是构建专门用于自主探索和发现的智能体 AI 系统。这些系统通常利用多智能体框架,其中专门的大语言模型协作以模拟科学方法等过程。例如,可以为不同的智能体分配生成假设、批判性审查它们以及发展最有前途的概念的任务。这种结构化的协作方法允许系统智能地导航庞大的信息格局、设计和执行实验并生成真正的新知识。通过自动化探索的劳动密集型方面,这些系统增强了人类智力并显著加速了发现的步伐。
Rule of thumb: Use the Exploration and Discovery pattern when operating in open-ended, complex, or rapidly evolving domains where the solution space is not fully defined. It is ideal for tasks requiring the generation of novel hypotheses, strategies, or insights, such as in scientific research, market analysis, and creative content generation. This pattern is essential when the objective is to uncover “unknown unknowns” rather than merely optimizing a known process.
实践建议:当在开放式、复杂或快速演变的领域中运行时,使用探索和发现模式,在这些领域中解决方案空间没有完全定义。它非常适合需要生成新假设、策略或见解的任务,例如科学研究、市场分析和创意内容生成。当目标是发现”未知的未知因素”而不仅仅是优化已知过程时,此模式至关重要。
Visual summary
可视化摘要
Fig.2: Exploration and Discovery design pattern
图 2:探索和发现设计模式
Key Takeaways
关键要点
- Exploration and Discovery in AI enable agents to actively pursue new information and possibilities, which is essential for navigating complex and evolving environments.
- Systems such as Google Co-Scientist demonstrate how Agents can autonomously generate hypotheses and design experiments, supplementing human scientific research.
- The multi-agent framework, exemplified by Agent Laboratory’s specialized roles, improves research through the automation of literature review, experimentation, and report writing.
-
Ultimately, these Agents aim to enhance human creativity and problem-solving by managing computationally intensive tasks, thus accelerating innovation and discovery.
- AI 中的探索和发现使智能体能够主动追求新信息和可能性,这对于在复杂和不断演变的环境中导航至关重要。
- Google 协同科学家等系统展示了智能体如何自主生成假设和设计实验,补充人类科学研究。
- 多智能体框架(例如 Agent Laboratory 的专门角色)通过自动化文献综述、实验和报告撰写来改进研究。
- 最终,这些智能体旨在通过管理计算密集型任务来增强人类创造力和问题解决能力,从而加速创新和发现。
Conclusion
结论
In conclusion, the Exploration and Discovery pattern is the very essence of a truly agentic system, defining its ability to move beyond passive instruction-following to proactively explore its environment. This innate agentic drive is what empowers an AI to operate autonomously in complex domains, not merely executing tasks but independently setting sub-goals to uncover novel information. This advanced agentic behavior is most powerfully realized through multi-agent frameworks where each agent embodies a specific, proactive role in a larger collaborative process. For instance, the highly agentic system of Google’s Co-scientist features agents that autonomously generate, debate, and evolve scientific hypotheses.
总之,探索和发现模式是真正智能体系统的本质,定义了其超越被动指令跟随来主动探索其环境的能力。这种与生俱来的智能体驱动力使 AI 能够在复杂领域中自主运行,不仅执行任务,而且独立设定子目标以发现新信息。这种高级智能体行为通过多智能体框架最有力地实现,其中每个智能体在大的协作过程中体现特定的主动角色。例如,Google 协同科学家的高度智能体系统具有自主生成、辩论和发展科学假设的智能体。
Frameworks like Agent Laboratory further structure this by creating an agentic hierarchy that mimics human research teams, enabling the system to self-manage the entire discovery lifecycle. The core of this pattern lies in orchestrating emergent agentic behaviors, allowing the system to pursue long-term, open-ended goals with minimal human intervention. This elevates the human-AI partnership, positioning the AI as a genuine agentic collaborator that handles the autonomous execution of exploratory tasks. By delegating this proactive discovery work to an agentic system, human intellect is significantly augmented, accelerating innovation. The development of such powerful agentic capabilities also necessitates a strong commitment to safety and ethical oversight. Ultimately, this pattern provides the blueprint for creating truly agentic AI, transforming computational tools into independent, goal-seeking partners in the pursuit of knowledge.
像 Agent Laboratory 这样的框架通过创建模仿人类研究团队的智能体层次结构进一步构建这一点,使系统能够自我管理整个发现生命周期。该模式的核心在于编排新兴的智能体行为,允许系统以最少的人工干预来追求长期的、开放式的目标。这提升了人机合作关系,将 AI 定位为真正的智能体协作者,处理探索性任务的自主执行。通过将这种主动发现工作委托给智能体系统,人类智力得到显著增强,创新得以加速。开发这种强大的智能体能力也需要对安全性和道德监督做出强有力的承诺。最终,这种模式提供了创建真正智能体 AI 的蓝图,将计算工具转变为追求知识的独立的、目标寻求的伙伴。
References
参考文献
- Exploration-Exploitation Dilemma: A fundamental problem in reinforcement learning and decision-making under uncertainty. https://en.wikipedia.org/wiki/Exploration%E2%80%93exploitation_dilemma
- Google Co-Scientist: https://research.google/blog/accelerating-scientific-breakthroughs-with-an-ai-co-scientist/
- Agent Laboratory: Using LLM Agents as Research Assistants https://github.com/SamuelSchmidgall/AgentLaboratory
- AgentRxiv: Towards Collaborative Autonomous Research: https://agentrxiv.github.io/