Chapter 1: Prompt Chaining
第 1 章:提示词链
Prompt Chaining Pattern Overview
提示词链模式概述
Prompt chaining, sometimes referred to as Pipeline pattern, represents a powerful paradigm for handling intricate tasks when leveraging large language models (LLMs). Rather than expecting an LLM to solve a complex problem in a single, monolithic step, prompt chaining advocates for a divide-and-conquer strategy. The core idea is to break down the original, daunting problem into a sequence of smaller, more manageable sub-problems. Each sub-problem is addressed individually through a specifically designed prompt, and the output generated from one prompt is strategically fed as input into the subsequent prompt in the chain.
提示词链(Prompt Chaining),有时也称为管道模式(Pipeline pattern),是利用大型语言模型(LLM)处理复杂任务的强大范式。这种方法不再要求 LLM 在单一的整体化步骤中解决复杂问题,而是采用分而治之的策略:将原本令人却步的问题分解为一系列更小、更易管理的子问题,每个子问题通过专门设计的提示词单独处理,一个提示词的输出会作为输入策略性地传递给链中的下一个提示词。
This sequential processing technique inherently introduces modularity and clarity into the interaction with LLMs. By decomposing a complex task, it becomes easier to understand and debug each individual step, making the overall process more robust and interpretable. Each step in the chain can be meticulously crafted and optimized to focus on a specific aspect of the larger problem, leading to more accurate and focused outputs.
这种顺序处理技术天然地为与 LLM 的交互引入了模块化和清晰性。通过分解复杂任务,每个单独的步骤都变得更容易理解和调试,使整个过程更加健壮和可解释。链中的每一步都可以精心设计和优化,专注于更大问题的特定方面,从而产生更准确、更聚焦的输出。
The output of one step acting as the input for the next is crucial. This passing of information establishes a dependency chain, hence the name, where the context and results of previous operations guide the subsequent processing. This allows the LLM to build on its previous work, refine its understanding, and progressively move closer to the desired solution.
一个步骤的输出作为下一个步骤的输入至关重要。这种信息传递建立了依赖链(因此得名),其中先前操作的上下文和结果指导后续处理。这使得 LLM 能够在其先前工作的基础上构建,完善理解,并逐步接近期望的解决方案。
Furthermore, prompt chaining is not just about breaking down problems; it also enables the integration of external knowledge and tools. At each step, the LLM can be instructed to interact with external systems, APIs, or databases, enriching its knowledge and abilities beyond its internal training data. This capability dramatically expands the potential of LLMs, allowing them to function not just as isolated models but as integral components of broader, more intelligent systems.
此外,提示词链不仅仅是分解问题;它还支持集成外部知识和工具。在每一步,都可以指示 LLM 与外部系统、API 或数据库交互,从而丰富其内部训练数据之外的知识和能力。这种能力极大地扩展了 LLM 的潜力,使它们不再只是作为独立模型运行,而是成为更广泛、更智能系统的组成部分。
The significance of prompt chaining extends beyond simple problem-solving. It serves as a foundational technique for building sophisticated AI agents. These agents can utilize prompt chains to autonomously plan, reason, and act in dynamic environments. By strategically structuring the sequence of prompts, an agent can engage in tasks requiring multi-step reasoning, planning, and decision-making. Such agent workflows can mimic human thought processes more closely, allowing for more natural and effective interactions with complex domains and systems.
提示词链的重要性超越了简单的问题解决。它是构建复杂 AI 智能体系统的基础技术。这些智能体可以利用提示词链在动态环境中自主规划、推理和行动。通过策略性地构建提示词序列,智能体可以参与需要多步推理、规划和决策的任务。这样的智能体工作流可以更紧密地模拟人类思维过程,从而实现与复杂领域和系统更自然、更有效的交互。
Limitations of single prompts: For multifaceted tasks, using a single, complex prompt for an LLM can be inefficient, causing the model to struggle with constraints and instructions, potentially leading to instruction neglect where parts of the prompt are overlooked, contextual drift where the model loses track of the initial context, error propagation where early errors amplify, prompts which require a longer context window where the model gets insufficient information to respond back and hallucination where the cognitive load increases the chance of incorrect information. For example, a query asking to analyze a market research report, summarize findings, identify trends with data points, and draft an email risks failure as the model might summarize well but fail to extract data or draft an email properly.
单一提示词的局限性: 对于多维度任务,使用单一的复杂提示词往往效率低下。LLM 可能难以处理多重约束和指令,导致以下问题:
- 指令忽略:部分提示内容被忽视
- 上下文偏离:模型失去对初始上下文的追踪
- 错误传播:早期错误被放大
- 上下文窗口不足:模型获取的信息不足以生成响应
- 幻觉:认知负荷增加导致生成错误信息
例如,要求分析市场研究报告、总结发现、识别趋势并起草邮件的查询可能会失败——模型可能很好地完成总结,但无法正确提取数据或起草邮件。
Enhanced Reliability Through Sequential Decomposition: Prompt chaining addresses these challenges by breaking the complex task into a focused, sequential workflow, which significantly improves reliability and control. Given the example above, a pipeline or chained approach can be described as follows:
通过顺序分解增强可靠性: 提示词链通过将复杂任务分解为聚焦的、顺序的工作流来解决这些挑战,显著提高了可靠性和控制力。基于上面的例子,管道或链式方法可以描述如下:
- Initial Prompt (Summarization): “Summarize the key findings of the following market research report: [text].” The model’s sole focus is summarization, increasing the accuracy of this initial step.
- Second Prompt (Trend Identification): “Using the summary, identify the top three emerging trends and extract the specific data points that support each trend: [output from step 1].” This prompt is now more constrained and builds directly upon a validated output.
-
Third Prompt (Email Composition): “Draft a concise email to the marketing team that outlines the following trends and their supporting data: [output from step 2].”
- 初始提示词(总结):”总结以下市场研究报告的主要发现:[文本]。” 模型的唯一焦点是总结,提高了这一初始步骤的准确性。
- 第二个提示词(趋势识别):”使用摘要,识别前三个新兴趋势并提取支持每个趋势的具体数据点:[步骤 1 的输出]。” 此提示词现在更受约束,并直接建立在经过验证的输出之上。
- 第三个提示词(电子邮件撰写):”向营销团队起草一封简明的电子邮件,概述以下趋势及其支持数据:[步骤 2 的输出]。”
This decomposition allows for more granular control over the process. Each step is simpler and less ambiguous, which reduces the cognitive load on the model and leads to a more accurate and reliable final output. This modularity is analogous to a computational pipeline where each function performs a specific operation before passing its result to the next. To ensure an accurate response for each specific task, the model can be assigned a distinct role at every stage. For example, in the given scenario, the initial prompt could be designated as “Market Analyst,” the subsequent prompt as “Trade Analyst,” and the third prompt as “Expert Documentation Writer,” and so forth.
这种分解提供了对流程更精细的控制。每个简化步骤减少了模型的认知负荷,产生更准确可靠的输出。这种模块化类似于计算流水线,每个函数执行特定操作后传递结果。为确保各步骤的准确性,可以在每个阶段为模型分配不同角色,例如:初始提示词作为”市场分析师”,后续提示词作为”贸易分析师”,第三个提示词作为”专业文档撰写者”等等。
The Role of Structured Output: The reliability of a prompt chain is highly dependent on the integrity of the data passed between steps. If the output of one prompt is ambiguous or poorly formatted, the subsequent prompt may fail due to faulty input. To mitigate this, specifying a structured output format, such as JSON or XML, is crucial.
For example, the output from the trend identification step could be formatted as a JSON object:
1
2
3
4
5
6
7
8
9
10
11
12
{
"trends": [
{
"trend_name": "AI-Powered Personalization",
"supporting_data": "73% of consumers prefer to do business with brands that use personal information to make their shopping experiences more relevant."
},
{
"trend_name": "Sustainable and Ethical Brands",
"supporting_data": "Sales of products with ESG-related claims grew 28% over the last five years, compared to 20% for products without."
}
]
}
This structured format ensures that the data is machine-readable and can be precisely parsed and inserted into the next prompt without ambiguity. This practice minimizes errors that can arise from interpreting natural language and is a key component in building robust, multi-step LLM-based systems.
结构化输出的作用: 提示词链的可靠性高度依赖于步骤之间传递的数据完整性。如果一个提示词的输出不明确或格式不佳,后续提示词可能由于错误的输入而失败。为了缓解这一问题,指定结构化输出格式(如 JSON 或 XML)至关重要。
例如,趋势识别步骤的输出可以格式化为 JSON 对象:
这种结构化格式确保数据是机器可读的,可以精确解析并无歧义地插入到下一个提示词中。该实践最小化了自然语言解释可能导致的错误,是构建健壮的多步骤 LLM 系统的关键组件。
Practical Applications & Use Cases
实际应用与用例
Prompt chaining is a versatile pattern applicable in a wide range of scenarios when building agentic systems. Its core utility lies in breaking down complex problems into sequential, manageable steps. Here are several practical applications and use cases:
提示词链是一种多用途模式,在构建智能体系统时适用于广泛的场景。其核心效用在于将复杂问题分解为顺序的、可管理的步骤。以下是几个实际应用和用例:
1. Information Processing Workflows: Many tasks involve processing raw information through multiple transformations. For instance, summarizing a document, extracting key entities, and then using those entities to query a database or generate a report. A prompt chain could look like:
1. 信息处理工作流: 许多任务涉及通过多次转换处理原始信息。例如,总结文档、提取关键实体,然后使用这些实体查询数据库或生成报告。提示词链可能如下所示:
- Prompt 1: Extract text content from a given URL or document.
- Prompt 2: Summarize the cleaned text.
- Prompt 3: Extract specific entities (e.g., names, dates, locations) from the summary or original text.
- Prompt 4: Use the entities to search an internal knowledge base.
-
Prompt 5: Generate a final report incorporating the summary, entities, and search results.
- 提示词 1:从给定的 URL 或文档中提取文本内容。
- 提示词 2:总结清理后的文本。
- 提示词 3:从摘要或原始文本中提取特定实体(例如,姓名、日期、位置)。
- 提示词 4:使用实体搜索内部知识库。
- 提示词 5:生成包含摘要、实体和搜索结果的最终报告。
This methodology is applied in domains such as automated content analysis, the development of AI-driven research assistants, and complex report generation.
这种方法应用于自动化内容分析、AI 驱动的研究助手开发和复杂报告生成等领域。
2. Complex Query Answering: Answering complex questions that require multiple steps of reasoning or information retrieval is a prime use case. For example, “What were the main causes of the stock market crash in 1929, and how did government policy respond?”
2. 复杂查询回答: 回答需要多步推理或信息检索的复杂问题是一个主要用例。例如,”1929 年股市崩盘的主要原因是什么,政府政策如何应对?”
- Prompt 1: Identify the core sub-questions in the user’s query (causes of crash, government response).
- Prompt 2: Research or retrieve information specifically about the causes of the 1929 crash.
- Prompt 3: Research or retrieve information specifically about the government’s policy response to the 1929 stock market crash.
-
Prompt 4: Synthesize the information from steps 2 and 3 into a coherent answer to the original query.
- 提示词 1:识别用户查询中的核心子问题(崩盘原因、政府响应)。
- 提示词 2:专门研究或检索有关 1929 年崩盘原因的信息。
- 提示词 3:专门研究或检索有关政府对 1929 年股市崩盘的政策响应的信息。
- 提示词 4:将步骤 2 和 3 的信息综合成对原始查询的连贯答案。
This sequential processing methodology is integral to developing AI systems capable of multi-step inference and information synthesis. Such systems are required when a query cannot be answered from a single data point but instead necessitates a series of logical steps or the integration of information from diverse sources.
这种顺序处理方法是开发能够进行多步推理和信息综合的 AI 系统的核心。当查询无法从单个数据点回答,而是需要一系列逻辑步骤或来自不同来源的信息集成时,就需要这样的系统。
For example, an automated research agent designed to generate a comprehensive report on a specific topic executes a hybrid computational workflow. Initially, the system retrieves numerous relevant articles. The subsequent task of extracting key information from each article can be performed concurrently for each source. This stage is well-suited for parallel processing, where independent sub-tasks are run simultaneously to maximize efficiency.
例如,设计用于生成关于特定主题的综合报告的自动化研究智能体,会执行混合计算工作流。最初,系统检索大量相关文章。从每篇文章中提取关键信息的后续任务可以为每个来源并发执行。此阶段非常适合并行处理,其中独立的子任务同时运行以最大化效率。
However, once the individual extractions are complete, the process becomes inherently sequential. The system must first collate the extracted data, then synthesize it into a coherent draft, and finally review and refine this draft to produce a final report. Each of these later stages is logically dependent on the successful completion of the preceding one. This is where prompt chaining is applied: the collated data serves as the input for the synthesis prompt, and the resulting synthesized text becomes the input for the final review prompt. Therefore, complex operations frequently combine parallel processing for independent data gathering with prompt chaining for the dependent steps of synthesis and refinement.
然而,一旦单个提取完成,过程在本质上就变为顺序的了。系统必须首先整合提取的数据,然后将其综合成连贯的草稿,最后审查和完善这份草稿以生成最终报告。后面的每个阶段在逻辑上都依赖于前一阶段的成功完成。这就是提示词链的应用场景:整合后的数据作为综合提示词的输入,而综合后的文本又成为最终审查提示词的输入。因此,复杂操作经常将并行处理用于独立数据收集,而将提示词链用于综合和完善等有依赖关系的步骤。
3. Data Extraction and Transformation: The conversion of unstructured text into a structured format is typically achieved through an iterative process, requiring sequential modifications to improve the accuracy and completeness of the output.
3. 数据提取和转换: 将非结构化文本转换为结构化格式通常通过迭代过程实现,需要顺序修改以提高输出的准确性和完整性。
- Prompt 1: Attempt to extract specific fields (e.g., name, address, amount) from an invoice document.
- Processing: Check if all required fields were extracted and if they meet format requirements.
- Prompt 2 (Conditional): If fields are missing or malformed, craft a new prompt asking the model to specifically find the missing/malformed information, perhaps providing context from the failed attempt.
- Processing: Validate the results again. Repeat if necessary.
-
Output: Provide the extracted, validated structured data.
- 提示词 1:尝试从发票文档中提取特定字段(例如,姓名、地址、金额)。
- 处理:检查是否提取了所有必需字段以及它们是否满足格式要求。
- 提示词 2(条件性):如果字段缺失或格式错误,制作新提示词要求模型专门查找缺失/格式错误的信息,可能提供失败尝试的上下文。
- 处理:再次验证结果。如有必要重复。
- 输出:提供提取的、验证的结构化数据。
This sequential processing methodology is particularly applicable to data extraction and analysis from unstructured sources like forms, invoices, or emails. For example, solving complex Optical Character Recognition (OCR) problems, such as processing a PDF form, is more effectively handled through a decomposed, multi-step approach.
这种顺序处理方法特别适用于从表单、发票或电子邮件等非结构化来源进行数据提取和分析。例如,解决复杂的光学字符识别(OCR)问题,如处理 PDF 表单,通过分解的多步方法能更有效地处理。
Initially, a large language model is employed to perform the primary text extraction from the document image. Following this, the model processes the raw output to normalize the data, a step where it might convert numeric text, such as “one thousand and fifty,” into its numerical equivalent, 1050. A significant challenge for LLMs is performing precise mathematical calculations. Therefore, in a subsequent step, the system can delegate any required arithmetic operations to an external calculator tool. The LLM identifies the necessary calculation, feeds the normalized numbers to the tool, and then incorporates the precise result. This chained sequence of text extraction, data normalization, and external tool use achieves a final, accurate result that is often difficult to obtain reliably from a single LLM query.
首先,使用大型语言模型从文档图像执行主要文本提取。随后,模型处理原始输出以规范化数据,在这一步中,它可能会将数字文本(如”一千零五十”)转换为其数字等价形式 1050。LLM 面临的一个重大挑战是执行精确的数学计算。因此,在后续步骤中,系统可以将任何所需的算术运算委托给外部计算器工具。LLM 识别所需的计算,将规范化后的数字输入该工具,然后整合精确的结果。这种文本提取、数据规范化和外部工具使用的链式序列,实现了通常难以通过单个 LLM 查询可靠获得的最终准确结果。
4. Content Generation Workflows: The composition of complex content is a procedural task that is typically decomposed into distinct phases, including initial ideation, structural outlining, drafting, and subsequent revision
4. 内容生成工作流: 复杂内容的创作是一个程序化任务,通常分解为不同的阶段,包括初始构思、结构大纲、起草和后续修订。
- Prompt 1: Generate 5 topic ideas based on a user’s general interest.
- Processing: Allow the user to select one idea or automatically choose the best one.
- Prompt 2: Based on the selected topic, generate a detailed outline.
- Prompt 3: Write a draft section based on the first point in the outline.
- Prompt 4: Write a draft section based on the second point in the outline, providing the previous section for context. Continue this for all outline points.
-
Prompt 5: Review and refine the complete draft for coherence, tone, and grammar.
- 提示词 1:根据用户的一般兴趣生成 5 个主题想法。
- 处理:允许用户选择一个想法或自动选择最佳想法。
- 提示词 2:基于选定的主题,生成详细的大纲。
- 提示词 3:根据大纲中的第一点编写草稿部分。
- 提示词 4:根据大纲中的第二点编写草稿部分,提供前一部分作为上下文。对所有大纲点继续这样做。
- 提示词 5:审查和完善完整草稿的连贯性、语气和语法。
This methodology is employed for a range of natural language generation tasks, including the automated composition of creative narratives, technical documentation, and other forms of structured textual content.
这种方法用于一系列自然语言生成任务,包括创意叙事、技术文档和其他形式的结构化文本内容的自动创作。
5. Conversational Agents with State: Although comprehensive state management architectures employ methods more complex than sequential linking, prompt chaining provides a foundational mechanism for preserving conversational continuity. This technique maintains context by constructing each conversational turn as a new prompt that systematically incorporates information or extracted entities from preceding interactions in the dialogue sequence.
5. 具有状态的对话智能体系统: 尽管全面的状态管理架构采用比顺序链接更复杂的方法,提示词链提供了保持对话连续性的基础机制。这种技术通过将每个对话轮次构建为新提示词来维护上下文,该提示词系统地合并来自对话序列中先前交互的信息或提取的实体。
- Prompt 1: Process User Utterance 1, identify intent and key entities.
- Processing: Update conversation state with intent and entities.
- Prompt 2: Based on current state, generate a response and/or identify the next required piece of information.
-
Repeat for subsequent turns, with each new user utterance initiating a chain that leverages the accumulating conversation history (state).
- 提示词 1:处理用户话语 1,识别意图和关键实体。
- 处理:使用意图和实体更新对话状态。
- 提示词 2:基于当前状态,生成响应和/或识别下一个所需的信息片段。
- 对于后续轮次重复,每个新的用户话语启动一个利用累积对话历史(状态)的链。
This principle is fundamental to the development of conversational agents, enabling them to maintain context and coherence across extended, multi-turn dialogues. By preserving the conversational history, the system can understand and appropriately respond to user inputs that depend on previously exchanged information.
这一原则是开发对话智能体系统的基础,使它们能够在扩展的、多轮对话中保持上下文和连贯性。通过保留对话历史,系统可以理解并适当响应依赖于先前交换信息的用户输入。
6. Code Generation and Refinement: The generation of functional code is typically a multi-stage process, requiring a problem to be decomposed into a sequence of discrete logical operations that are executed progressively
6. 代码生成和完善: 功能代码的生成通常是一个多阶段过程,需要将问题分解为逐步执行的离散逻辑操作序列。
- Prompt 1: Understand the user’s request for a code function. Generate pseudocode or an outline.
- Prompt 2: Write the initial code draft based on the outline.
- Prompt 3: Identify potential errors or areas for improvement in the code (perhaps using a static analysis tool or another LLM call).
- Prompt 4: Rewrite or refine the code based on the identified issues.
-
Prompt 5: Add documentation or test cases.
- 提示词 1:理解用户对代码函数的请求。生成伪代码或大纲。
- 提示词 2:基于大纲编写初始代码草稿。
- 提示词 3:识别代码中的潜在错误或改进领域(可能使用静态分析工具或另一个 LLM 调用)。
- 提示词 4:基于识别的问题重写或完善代码。
- 提示词 5:添加文档或测试用例。
In applications such as AI-assisted software development, the utility of prompt chaining stems from its capacity to decompose complex coding tasks into a series of manageable sub-problems. This modular structure reduces the operational complexity for the large language model at each step. Critically, this approach also allows for the insertion of deterministic logic between model calls, enabling intermediate data processing, output validation, and conditional branching within the workflow. By this method, a single, multifaceted request that could otherwise lead to unreliable or incomplete results is converted into a structured sequence of operations managed by an underlying execution framework.
在 AI 辅助软件开发等应用中,提示词链的价值源于其将复杂编码任务分解为一系列可管理子问题的能力。这种模块化结构降低了大型语言模型在每一步的操作复杂度。关键的是,这种方法还允许在模型调用之间插入确定性逻辑,从而在工作流中实现中间数据处理、输出验证和条件分支。通过这种方法,一个可能导致不可靠或不完整结果的单一多面请求,被转换为由底层执行框架管理的结构化操作序列。
7. Multimodal and multi-step reasoning: Analyzing datasets with diverse modalities necessitates breaking down the problem into smaller, prompt-based tasks. For example, interpreting an image that contains a picture with embedded text, labels highlighting specific text segments, and tabular data explaining each label, requires such an approach.
7. 多模态和多步推理: 分析具有不同模态的数据集需要将问题分解为更小的、基于提示词的任务。例如,解释包含带嵌入文本的图片、突出显示特定文本段的标签以及解释每个标签的表格数据的图像,就需要这样的方法。
- Prompt 1: Extract and comprehend the text from the user’s image request.
- Prompt 2: Link the extracted image text with its corresponding labels.
-
Prompt 3: Interpret the gathered information using a table to determine the required output.
- 提示词 1:从用户的图像请求中提取和理解文本。
- 提示词 2:将提取的图像文本与其相应的标签链接起来。
- 提示词 3:使用表格解释收集的信息以确定所需的输出。
Hands-On Code Example
实操代码示例
Implementing prompt chaining ranges from direct, sequential function calls within a script to the utilization of specialized frameworks designed to manage control flow, state, and component integration. Frameworks such as LangChain, LangGraph, Crew AI, and the Google Agent Development Kit (ADK) offer structured environments for constructing and executing these multi-step processes, which is particularly advantageous for complex architectures.
实现提示词链的范围从脚本中的直接顺序工具调用,到利用专门设计用于管理控制流、状态和组件集成的框架。诸如 LangChain、LangGraph、Crew AI 和 Google 智能体开发工具包(ADK)等框架,提供了用于构建和执行这些多步过程的结构化环境,这对于复杂架构特别有利。
For the purpose of demonstration, LangChain and LangGraph are suitable choices as their core APIs are explicitly designed for composing chains and graphs of operations. LangChain provides foundational abstractions for linear sequences, while LangGraph extends these capabilities to support stateful and cyclical computations, which are necessary for implementing more sophisticated agentic behaviors. This example will focus on a fundamental linear sequence.
出于演示目的,LangChain 和 LangGraph 是合适的选择,因为它们的核心 API 明确设计用于组合操作链和图。LangChain 为线性序列提供基础抽象,而 LangGraph 扩展了这些能力以支持状态化和循环计算,这对于实现更复杂的智能体行为是必需的。此示例将专注于基础线性序列。
The following code implements a two-step prompt chain that functions as a data processing pipeline. The initial stage is designed to parse unstructured text and extract specific information. The subsequent stage then receives this extracted output and transforms it into a structured data format.
以下代码实现了一个两步提示词链,作为数据处理管道运行。初始阶段旨在解析非结构化文本并提取特定信息。后续阶段然后接收此提取的输出并将其转换为结构化数据格式。
To replicate this procedure, the required libraries must first be installed. This can be accomplished using the following command:
1
pip install langchain langchain-community langchain-openai langgraph
Note that langchain-openai can be substituted with the appropriate package for a different model provider. Subsequently, the execution environment must be configured with the necessary API credentials for the selected language model provider, such as OpenAI, Google Gemini, or Anthropic.
This Python code demonstrates how to use the LangChain library to process text. It utilizes two separate prompts: one to extract technical specifications from an input string and another to format these specifications into a JSON object. The ChatOpenAI model is employed for language model interactions, and the StrOutputParser ensures the output is in a usable string format. The LangChain Expression Language (LCEL) is used to elegantly chain these prompts and the language model together. The first chain, extraction_chain, extracts the specifications. The full_chain then takes the output of the extraction and uses it as input for the transformation prompt. A sample input text describing a laptop is provided. The full_chain is invoked with this text, processing it through both steps. The final result, a JSON string containing the extracted and formatted specifications, is then printed.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
import os
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
## For better security, load environment variables from a .env file
## from dotenv import load_dotenv
## load_dotenv()
## Make sure your OPENAI_API_KEY is set in the .env file
## Initialize the Language Model (using ChatOpenAI is recommended)
llm = ChatOpenAI(temperature=0)
## --- Prompt 1: Extract Information ---
prompt_extract = ChatPromptTemplate.from_template(
"Extract the technical specifications from the following text:\n\n{text_input}"
)
## --- Prompt 2: Transform to JSON ---
prompt_transform = ChatPromptTemplate.from_template(
"Transform the following specifications into a JSON object with 'cpu', 'memory', and 'storage' as keys:\n\n{specifications}"
)
## --- Build the Chain using LCEL ---
## The StrOutputParser() converts the LLM's message output to a simple string.
extraction_chain = prompt_extract | llm | StrOutputParser()
## The full chain passes the output of the extraction chain into the 'specifications'
## variable for the transformation prompt.
full_chain = (
{"specifications": extraction_chain}
| prompt_transform
| llm
| StrOutputParser()
)
## --- Run the Chain ---
input_text = "The new laptop model features a 3.5 GHz octa-core processor, 16GB of RAM, and a 1TB NVMe SSD."
## Execute the chain with the input text dictionary.
final_result = full_chain.invoke({"text_input": input_text})
print("\n--- Final JSON Output ---")
print(final_result)
请注意,langchain-openai 可以替换为不同模型提供商的适当包。随后,必须为选定的语言模型提供商(如 OpenAI、Google Gemini 或 Anthropic)配置执行环境所需的 API 凭据。
这段 Python 代码演示了如何使用 LangChain 库处理文本。它利用两个独立的提示词:一个从输入字符串中提取技术规格,另一个将这些规格格式化为 JSON 对象。ChatOpenAI 模型用于语言模型交互,StrOutputParser 确保输出为可用的字符串格式。LangChain 表达式语言(LCEL)用于优雅地将这些提示词和语言模型链接在一起。第一个链 extraction_chain 提取规格。然后 full_chain 获取提取的输出,并将其用作转换提示词的输入。提供了描述笔记本电脑的示例输入文本。使用此文本调用 full_chain,通过两个步骤处理它。最后打印最终结果,即包含提取和格式化规格的 JSON 字符串。
Context Engineering and Prompt Engineering
上下文工程和提示工程
Context Engineering (see Fig.1) is the systematic discipline of designing, constructing, and delivering a complete informational environment to an AI model prior to token generation. This methodology asserts that the quality of a model’s output is less dependent on the model’s architecture itself and more on the richness of the context provided.
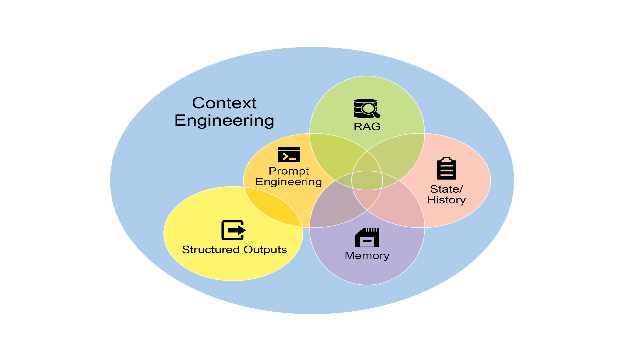
Fig.1: Context Engineering is the discipline of building a rich, comprehensive informational environment for an AI, as the quality of this context is a primary factor in enabling advanced Agentic performance.
上下文工程(见图 1)是在 token 生成之前系统地设计、构建和向 AI 模型提供完整信息环境的学科。这种方法论断言,模型输出的质量较少依赖于模型架构本身,而更多依赖于所提供上下文的丰富性。
图 1:上下文工程是为 AI 构建丰富、全面的信息环境的学科,因为此上下文的质量是实现高级智能体性能的主要因素。
It represents a significant evolution from traditional prompt engineering, which focuses primarily on optimizing the phrasing of a user’s immediate query. Context Engineering expands this scope to include several layers of information, such as the system prompt, which is a foundational set of instructions defining the AI’s operational parameters—for instance, “You are a technical writer; your tone must be formal and precise.” The context is further enriched with external data. This includes retrieved documents, where the AI actively fetches information from a knowledge base to inform its response, such as pulling technical specifications for a project. It also incorporates tool outputs, which are the results from the AI using an external API to obtain real-time data, like querying a calendar to determine a user’s availability. This explicit data is combined with critical implicit data, such as user identity, interaction history, and environmental state. The core principle is that even advanced models underperform when provided with a limited or poorly constructed view of the operational environment.
它代表着从传统提示工程的重大演进,传统提示工程主要专注于优化用户即时查询的措辞。上下文工程将这一范围扩展到包括多层信息,例如系统提示词,这是定义 AI 操作参数的基础指令集——例如,“你是一名技术作家;你的语气必须正式且精确”。上下文通过外部数据进一步丰富。这包括检索文档,其中 AI 主动从知识库获取信息以指导其响应,例如提取项目的技术规格。它还整合了工具输出,这是 AI 使用外部 API 获取实时数据的结果,例如查询日历以确定用户的可用性。这些显式数据与关键的隐式数据(如用户身份、交互历史和环境状态)相结合。核心原则是,即使是高级模型,在提供有限或构建不良的操作环境视图时也会表现不佳。
This practice, therefore, reframes the task from merely answering a question to building a comprehensive operational picture for the agent. For example, a context-engineered agent would not just respond to a query but would first integrate the user’s calendar availability (a tool output), the professional relationship with an email’s recipient (implicit data), and notes from previous meetings (retrieved documents). This allows the model to generate outputs that are highly relevant, personalized, and pragmatically useful. The “engineering” component involves creating robust pipelines to fetch and transform this data at runtime and establishing feedback loops to continually improve context quality.
因此,这种实践将任务从仅仅回答问题,重新定义为为智能体系统构建全面的操作图景。例如,上下文工程化的智能体不会仅仅响应查询,而是首先会整合用户的日历可用性(工具输出)、与电子邮件收件人的专业关系(隐式数据)以及之前会议的笔记(检索的文档)。这使得模型能够生成高度相关、个性化和实用的输出。”工程”组件涉及创建健壮的管道以在运行时获取和转换此数据,并建立反馈循环以持续改进上下文质量。
To implement this, specialized tuning systems can be used to automate the improvement process at scale. For example, tools like Google’s Vertex AI prompt optimizer can enhance model performance by systematically evaluating responses against a set of sample inputs and predefined evaluation metrics. This approach is effective for adapting prompts and system instructions across different models without requiring extensive manual rewriting. By providing such an optimizer with sample prompts, system instructions, and a template, it can programmatically refine the contextual inputs, offering a structured method for implementing the feedback loops required for sophisticated Context Engineering.
为实现这一点,可以使用专门的调优系统来大规模自动化改进过程。例如,Google Vertex AI 提示优化器等工具可以通过系统化地根据一组样本输入和预定义评估指标评估响应来提升模型性能。这种方法对于在不同模型间适配提示词和系统指令非常有效,无需大量手动重写。通过向这样的优化器提供样本提示、系统指令和模板,它可以可编程式地完善上下文输入,为实现复杂上下文工程所需的反馈循环提供结构化方法。
This structured approach is what differentiates a rudimentary AI tool from a more sophisticated and contextually-aware system. It treats the context itself as a primary component, placing critical importance on what the agent knows, when it knows it, and how it uses that information. The practice ensures the model has a well-rounded understanding of the user’s intent, history, and current environment. Ultimately, Context Engineering is a crucial methodology for advancing stateless chatbots into highly capable, situationally-aware systems.
这种结构化方法是区分基本 AI 工具与更复杂、上下文感知系统的关键。它将上下文本身视为主要组件,对智能体系统知道什么、何时知道以及如何使用该信息给予关键重要性。这种实践确保模型对用户的意图、历史和当前环境有全面的理解。最终,上下文工程是将无状态聊天机器人提升为高度能干、情境感知系统的关键方法论。
At a Glance
速览
What: Complex tasks often overwhelm LLMs when handled within a single prompt, leading to significant performance issues. The cognitive load on the model increases the likelihood of errors such as overlooking instructions, losing context, and generating incorrect information. A monolithic prompt struggles to manage multiple constraints and sequential reasoning steps effectively. This results in unreliable and inaccurate outputs, as the LLM fails to address all facets of the multifaceted request.
问题背景: 复杂任务在单个提示词内处理时通常会使 LLM 不堪重负,导致严重的性能问题。模型的认知负荷增加了错误的可能性,如忽略指令、失去上下文和生成错误信息。单体提示词难以有效管理多个约束和顺序推理步骤。这导致不可靠和不准确的输出,因为 LLM 未能解决多方面请求的所有方面。
Why: Prompt chaining provides a standardized solution by breaking down a complex problem into a sequence of smaller, interconnected sub-tasks. Each step in the chain uses a focused prompt to perform a specific operation, significantly improving reliability and control. The output from one prompt is passed as the input to the next, creating a logical workflow that progressively builds towards the final solution. This modular, divide-and-conquer strategy makes the process more manageable, easier to debug, and allows for the integration of external tools or structured data formats between steps. This pattern is foundational for developing sophisticated, multi-step Agentic systems that can plan, reason, and execute complex workflows.
解决方案: 提示词链通过将复杂问题分解为一系列较小的、相互关联的子任务来提供标准化解决方案。链中的每一步使用聚焦的提示词执行特定操作,显著提高可靠性和控制力。一个提示词的输出作为下一个提示词的输入传递,创建逐步构建最终解决方案的逻辑工作流。这种模块化的分而治之策略使过程更易于管理、更易于调试,并允许在步骤之间集成外部工具或结构化数据格式。这种模式是开发能够规划、推理和执行复杂工作流的复杂多步智能体系统的基础。
Rule of thumb: Use this pattern when a task is too complex for a single prompt, involves multiple distinct processing stages, requires interaction with external tools between steps, or when building Agentic systems that need to perform multi-step reasoning and maintain state.
实践建议: 当任务对于单个提示词过于复杂、涉及多个不同的处理阶段、需要在步骤之间与外部工具交互,或者在构建需要执行多步推理并维护状态的智能体系统时,使用此模式。
Visual summary
可视化摘要
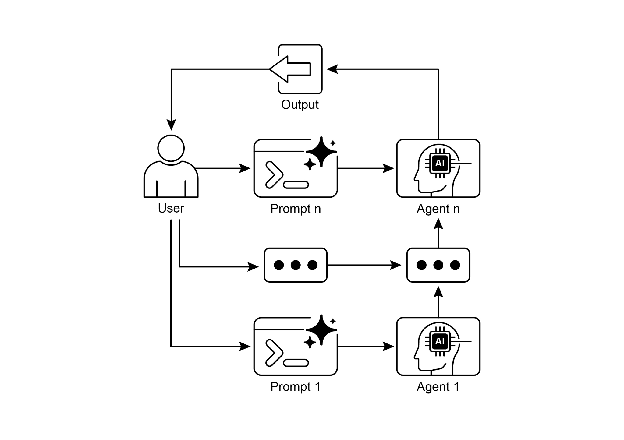
Fig. 2: Prompt Chaining Pattern: Agents receive a series of prompts from the user, with the output of each agent serving as the input for the next in the chain.
图 2:提示词链模式:智能体从用户接收一系列提示词,每个智能体的输出作为链中下一个智能体的输入
Key Takeaways
关键要点
Here are some key takeaways:
以下是一些关键要点:
- Prompt Chaining breaks down complex tasks into a sequence of smaller, focused steps. This is occasionally known as the Pipeline pattern.
- Each step in a chain involves an LLM call or processing logic, using the output of the previous step as input.
- This pattern improves the reliability and manageability of complex interactions with language models.
-
Frameworks like LangChain/LangGraph, and Google ADK provide robust tools to define, manage, and execute these multi-step sequences.
- 提示词链将复杂任务分解为一系列较小的、聚焦的步骤。这有时也被称为管道模式。
- 链中的每一步都涉及LLM调用或处理逻辑,使用前一步的输出作为输入。
- 这种模式提高了与语言模型进行复杂交互的可靠性和可管理性。
- LangChain/LangGraph和Google ADK等框架提供了定义、管理和执行这些多步序列的健壮工具。
Conclusion
结论
By deconstructing complex problems into a sequence of simpler, more manageable sub-tasks, prompt chaining provides a robust framework for guiding large language models. This “divide-and-conquer” strategy significantly enhances the reliability and control of the output by focusing the model on one specific operation at a time. As a foundational pattern, it enables the development of sophisticated AI agents capable of multi-step reasoning, tool integration, and state management. Ultimately, mastering prompt chaining is crucial for building robust, context-aware systems that can execute intricate workflows well beyond the capabilities of a single prompt.
通过将复杂问题分解为一系列更简单、更易于管理的子任务,提示词链为指导大型语言模型提供了一个健壮的框架。这种”分而治之”策略通过一次专注于一个特定操作,显著提高了输出的可靠性和控制力。作为基础模式,它支持开发能够进行多步推理、工具集成和状态管理的复杂 AI 智能体系统。最终,掌握提示词链对于构建能够执行远超单个提示词能力的复杂工作流的健壮、上下文感知系统至关重要。
References
参考文献
- LangChain Documentation on LCEL: https://python.langchain.com/v0.2/docs/core_modules/expression_language/
- LangGraph Documentation: https://langchain-ai.github.io/langgraph/
- Prompt Engineering Guide - Chaining Prompts: https://www.promptingguide.ai/techniques/chaining
- OpenAI API Documentation (General Prompting Concepts): https://platform.openai.com/docs/guides/gpt/prompting
- Crew AI Documentation (Tasks and Processes): https://docs.crewai.com/
- Google AI for Developers (Prompting Guides): https://cloud.google.com/discover/what-is-prompt-engineering?hl=en
- Vertex Prompt Optimizer https://cloud.google.com/vertex-ai/generative-ai/docs/learn/prompts/prompt-optimizer