Chapter 9: Learning and Adaptation
第 9 章:学习和适应
Learning and adaptation are pivotal for enhancing the capabilities of artificial intelligence agents. These processes enable agents to evolve beyond predefined parameters, allowing them to improve autonomously through experience and environmental interaction. By learning and adapting, agents can effectively manage novel situations and optimize their performance without constant manual intervention. This chapter explores the principles and mechanisms underpinning agent learning and adaptation in detail.
学习和适应能力对于提升人工智能智能体的能力至关重要。这些过程让智能体能够突破预设参数的限制,通过经验和环境交互实现自主提升。借助学习和适应,智能体无需持续的人工干预,就能有效应对新情况并优化自身表现。本章将深入探讨支撑智能体学习和适应的原理与机制。
The big picture
全局视野
Agents learn and adapt by changing their thinking, actions, or knowledge based on new experiences and data. This allows agents to evolve from simply following instructions to becoming smarter over time.
智能体通过基于新经验和数据改变思维方式、行动或知识来实现学习和适应。这让智能体从单纯遵循指令,逐步演变为随时间推移变得更加智能的系统。
- Reinforcement Learning: Agents try actions and receive rewards for positive outcomes and penalties for negative ones, learning optimal behaviors in changing situations. Useful for agents controlling robots or playing games.
- Supervised Learning: Agents learn from labeled examples, connecting inputs to desired outputs, enabling tasks like decision-making and pattern recognition. Ideal for agents sorting emails or predicting trends.
- Unsupervised Learning: Agents discover hidden connections and patterns in unlabeled data, aiding in insights, organization, and creating a mental map of their environment. Useful for agents exploring data without specific guidance.
- Few-Shot/Zero-Shot Learning with LLM-Based Agents: Agents leveraging LLMs can quickly adapt to new tasks with minimal examples or clear instructions, enabling rapid responses to new commands or situations.
- Online Learning: Agents continuously update knowledge with new data, essential for real-time reactions and ongoing adaptation in dynamic environments. Critical for agents processing continuous data streams.
-
Memory-Based Learning: Agents recall past experiences to adjust current actions in similar situations, enhancing context awareness and decision-making. Effective for agents with memory recall capabilities.
- 强化学习: 智能体尝试各种行动,对积极结果获得奖励,对消极结果受到惩罚,从而在动态环境中学习最优行为。适用于控制机器人或游戏角色的智能体。
- 监督学习: 智能体从标注示例中学习输入与期望输出的映射关系,支持决策制定和模式识别任务。适用于邮件分类或趋势预测的智能体。
- 无监督学习: 智能体在未标注数据中发现隐藏的模式和关联,构建环境的心理模型并获取洞察。适用于无需特定指导的数据探索场景。
- 基于大语言模型(LLM)的少样本/零样本学习: 利用大语言模型的智能体只需少量示例或明确指令,就能快速适应新任务,实现对新命令或情况的即时响应。
- 在线学习: 智能体持续更新知识库以适应动态环境,这对实时响应和持续优化至关重要。适用于处理连续数据流的智能体。
- 基于记忆的学习: 智能体回忆过往经验来调整当前行动,增强上下文感知和决策能力。特别适合具备记忆召回能力的智能体。
Agents adapt by changing strategy, understanding, or goals based on learning. This is vital for agents in unpredictable, changing, or new environments.
智能体通过基于学习结果改变策略、认知或目标来实现适应。这对于在不可预测、不断变化或全新环境中运行的智能体至关重要。
Proximal Policy Optimization (PPO) is a reinforcement learning algorithm used to train agents in environments with a continuous range of actions, like controlling a robot’s joints or a character in a game. Its main goal is to reliably and stably improve an agent’s decision-making strategy, known as its policy.
近端策略优化(PPO) 是一种强化学习算法,用于在动作范围连续的环境中训练智能体,例如控制机器人关节或游戏角色。其主要目标是可靠且稳定地改进智能体的决策策略(即策略)。
The core idea behind PPO is to make small, careful updates to the agent’s policy. It avoids drastic changes that could cause performance to collapse. Here’s how it works:
PPO 的核心思想是对智能体的策略进行小幅、谨慎的更新,避免可能导致性能崩溃的剧烈变化。其工作流程如下:
- Collect Data: The agent interacts with its environment (e.g., plays a game) using its current policy and collects a batch of experiences (state, action, reward).
- Evaluate a “Surrogate” Goal: PPO calculates how a potential policy update would change the expected reward. However, instead of just maximizing this reward, it uses a special “clipped” objective function.
-
The “Clipping” Mechanism: This is the key to PPO’s stability. It creates a “trust region” or a safe zone around the current policy. The algorithm is prevented from making an update that is too different from the current strategy. This clipping acts like a safety brake, ensuring the agent doesn’t take a huge, risky step that undoes its learning.
- 收集数据: 智能体使用当前策略与环境交互(例如玩游戏),收集一批经验数据(状态、动作、奖励)。
- 评估替代目标(Surrogate Goal): PPO 计算策略更新对预期奖励的影响,但它不只是单纯最大化奖励,而是使用一个特殊的”裁剪”目标函数。
- 裁剪机制: 这是 PPO 稳定性的关键。它在当前策略周围创建一个”信任区域”或安全区,阻止算法进行与当前策略差异过大的更新。这种裁剪机制就像一个安全刹车,确保智能体不会采取巨大而有风险的步骤,避免破坏已经学到的知识。
In short, PPO balances improving performance with staying close to a known, working strategy, which prevents catastrophic failures during training and leads to more stable learning.
简而言之,PPO 在提升性能与保持接近已知有效策略之间取得平衡,这可以防止训练期间的灾难性故障,实现更稳定的学习过程。
Direct Preference Optimization (DPO) is a more recent method designed specifically for aligning Large Language Models (LLMs) with human preferences. It offers a simpler, more direct alternative to using PPO for this task.
直接偏好优化(DPO) 是一种专门为使大语言模型与人类偏好保持一致而设计的更新方法。它为这项任务提供了比使用 PPO 更简单、更直接的替代方案。
To understand DPO, it helps to first understand the traditional PPO-based alignment method:
要理解 DPO,先了解传统的基于 PPO 的对齐方法会有所帮助:
- The PPO Approach (Two-Step Process):
- Train a Reward Model: First, you collect human feedback data where people rate or compare different LLM responses (e.g., “Response A is better than Response B”). This data is used to train a separate AI model, called a reward model, whose job is to predict what score a human would give to any new response.
- Fine-Tune with PPO: Next, the LLM is fine-tuned using PPO. The LLM’s goal is to generate responses that get the highest possible score from the reward model. The reward model acts as the “judge” in the training game.
- PPO 方法(两步过程):
- 训练奖励模型: 首先收集人类反馈数据,人们在其中对不同的 LLM 响应进行评级或比较(例如,”响应 A 比响应 B 更好”)。这些数据用于训练一个独立的 AI 模型,称为奖励模型,其任务是预测人类会给任何新响应打多少分。
- 使用 PPO 微调: 接下来使用 PPO 微调 LLM。LLM 的目标是生成能从奖励模型获得最高分的响应。奖励模型在训练过程中充当”评判员”。
This two-step process can be complex and unstable. For instance, the LLM might find a loophole and learn to “hack” the reward model to get high scores for bad responses.
这个两步过程可能既复杂又不稳定。例如,LLM 可能会找到漏洞,学会”破解”奖励模型,为质量较差的响应获得高分。
- The DPO Approach (Direct Process): DPO skips the reward model entirely. Instead of translating human preferences into a reward score and then optimizing for that score, DPO uses the preference data directly to update the LLM’s policy.
-
It works by using a mathematical relationship that directly links preference data to the optimal policy. It essentially teaches the model: “Increase the probability of generating responses like the preferred one and decrease the probability of generating ones like the disfavored one.”
- DPO 方法(直接过程): DPO 完全跳过了奖励模型。它不是将人类偏好转换为奖励分数然后优化该分数,而是直接使用偏好数据来更新 LLM 的策略。
- 它通过利用直接将偏好数据与最优策略联系起来的数学关系来工作。本质上,它教导模型:”增加生成类似偏好响应的概率,减少生成类似不受欢迎响应的概率。”
In essence, DPO simplifies alignment by directly optimizing the language model on human preference data. This avoids the complexity and potential instability of training and using a separate reward model, making the alignment process more efficient and robust.
本质上,DPO 通过直接在人类偏好数据上优化语言模型来简化对齐过程。这避免了训练和使用单独奖励模型的复杂性和潜在不稳定性,使对齐过程更高效、更稳健。
Practical Applications & Use Cases
实际应用与用例
Adaptive agents exhibit enhanced performance in variable environments through iterative updates driven by experiential data.
自适应智能体通过经验数据驱动的迭代更新,在多变环境中表现出更强的性能。
- Personalized assistant agents refine interaction protocols through longitudinal analysis of individual user behaviors, ensuring highly optimized response generation.
- Trading bot agents optimize decision-making algorithms by dynamically adjusting model parameters based on high-resolution, real-time market data, thereby maximizing financial returns and mitigating risk factors.
- Application agents optimize user interface and functionality through dynamic modification based on observed user behavior, resulting in increased user engagement and system intuitiveness.
- Robotic and autonomous vehicle agents enhance navigation and response capabilities by integrating sensor data and historical action analysis, enabling safe and efficient operation across diverse environmental conditions.
- Fraud detection agents improve anomaly detection by refining predictive models with newly identified fraudulent patterns, enhancing system security and minimizing financial losses.
- Recommendation agents improve content selection precision by employing user preference learning algorithms, providing highly individualized and contextually relevant recommendations.
- Game AI agents enhance player engagement by dynamically adapting strategic algorithms, thereby increasing game complexity and challenge.
-
Knowledge Base Learning Agents: Agents can leverage Retrieval Augmented Generation (RAG) to maintain a dynamic knowledge base of problem descriptions and proven solutions (see the Chapter 14). By storing successful strategies and challenges encountered, the agent can reference this data during decision-making, enabling it to adapt to new situations more effectively by applying previously successful patterns or avoiding known pitfalls.
- 个性化助手智能体: 通过长期分析用户行为模式优化交互方式,生成高度定制化的响应。
- 交易机器人智能体: 基于实时市场数据动态调整模型参数,优化决策算法并平衡风险与收益。
- 应用程序智能体: 根据用户行为动态修改界面功能,提升系统直观性和用户参与度。
- 机器人及自动驾驶智能体: 整合传感器数据和历史行动分析,实现各种环境下的安全高效操作。
- 欺诈检测智能体: 识别新型欺诈模式以改进预测模型,增强异常检测能力并减少损失。
- 推荐智能体: 采用用户偏好学习算法,提供高度个性化且与上下文相关的推荐。
- 游戏 AI 智能体: 动态调整战略算法以增加游戏复杂性和挑战性,提升玩家参与度。
- 知识库学习智能体: 智能体可以利用检索增强生成(RAG)维护问题描述和成功解决方案的动态知识库(参见第14章)。通过存储成功策略和遇到的挑战,智能体可以在决策时参考这些数据,通过应用之前成功的模式或避免已知陷阱,更有效地适应新情况。
Case Study: The Self-Improving Coding Agent (SICA)
案例研究:自我改进编码智能体(SICA)
The Self-Improving Coding Agent (SICA), developed by Maxime Robeyns, Laurence Aitchison, and Martin Szummer, represents an advancement in agent-based learning, demonstrating the capacity for an agent to modify its own source code. This contrasts with traditional approaches where one agent might train another; SICA acts as both the modifier and the modified entity, iteratively refining its code base to improve performance across various coding challenges.
自我改进编码智能体(SICA)由 Maxime Robeyns、Laurence Aitchison 和 Martin Szummer 开发,代表了基于智能体学习的重要进展,展示了智能体修改自身源代码的能力。这与传统方法形成鲜明对比——在传统方法中,一个智能体可能训练另一个智能体;而 SICA 既是修改者又是被修改的实体,通过迭代方式改进其代码库,以提升在各种编码挑战中的性能。
SICA’s self-improvement operates through an iterative cycle (see Fig.1). Initially, SICA reviews an archive of its past versions and their performance on benchmark tests. It selects the version with the highest performance score, calculated based on a weighted formula considering success, time, and computational cost. This selected version then undertakes the next round of self-modification. It analyzes the archive to identify potential improvements and then directly alters its codebase. The modified agent is subsequently tested against benchmarks, with the results recorded in the archive. This process repeats, facilitating learning directly from past performance. This self-improvement mechanism allows SICA to evolve its capabilities without requiring traditional training paradigms.
Fig.1: SICA’s self-improvement, learning and adapting based on its past versions
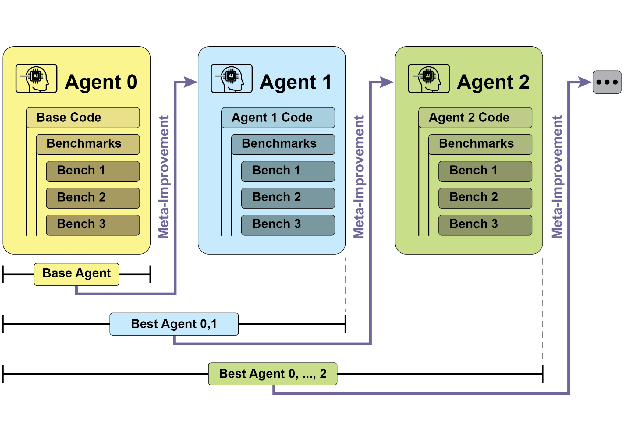
SICA 的自我改进通过一个迭代循环实现(见图1)。首先,SICA 审查其历史版本档案及其在基准测试中的表现,选择基于成功率、时间和计算成本的加权公式计算出的性能得分最高的版本。这个选定版本然后进行下一轮自我修改:它分析档案以识别潜在改进点,然后直接修改代码库。修改后的智能体随后接受基准测试,结果记录在档案中。这个过程不断重复,促进直接从过去表现中学习。这种自我改进机制让 SICA 无需传统训练范式就能进化其能力。
图 1:SICA 的自我改进过程,基于其过去版本进行学习和适应
SICA 经历了显著的自我改进,在代码编辑和导航方面取得了重要进展。最初,SICA 使用基本的文件覆盖方法进行代码更改。随后,它开发了能够进行更智能和上下文相关编辑的”智能编辑器”。这进一步演变为”差异增强智能编辑器”,结合差异进行有针对性的修改和基于模式的编辑,以及”快速覆盖工具”以减少处理需求。
SICA further implemented “Minimal Diff Output Optimization” and “Context-Sensitive Diff Minimization,” using Abstract Syntax Tree (AST) parsing for efficiency. Additionally, a “SmartEditor Input Normalizer” was added. In terms of navigation, SICA independently created an “AST Symbol Locator,” using the code’s structural map (AST) to identify definitions within the codebase. Later, a “Hybrid Symbol Locator” was developed, combining a quick search with AST checking. This was further optimized via “Optimized AST Parsing in Hybrid Symbol Locator” to focus on relevant code sections, improving search speed.(see Fig. 2)
Fig.2 : Performance across iterations. Key improvements are annotated with their corresponding tool or agent modifications. (courtesy of Maxime Robeyns , Martin Szummer , Laurence Aitchison)
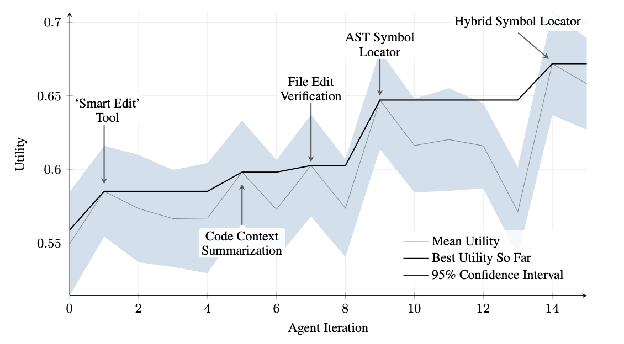
SICA 进一步实现了”最小差异输出优化”和”上下文敏感差异最小化”,使用抽象语法树(AST)解析来提高效率。此外,还添加了”智能编辑器输入规范化器”。在导航方面,SICA 独立创建了”AST 符号定位器”,使用代码的结构图(AST)来识别代码库中的定义。后来,开发了”混合符号定位器”,将快速搜索与 AST 检查相结合。这通过”混合符号定位器中的优化 AST 解析”进一步优化,专注于相关代码部分,提高搜索速度(见图2)。
图 2:跨迭代的性能表现。关键改进用其相应的工具或智能体修改进行标注。(由 Maxime Robeyns、Martin Szummer、Laurence Aitchison 提供)
SICA’s architecture comprises a foundational toolkit for basic file operations, command execution, and arithmetic calculations. It includes mechanisms for result submission and the invocation of specialized sub-agents (coding, problem-solving, and reasoning). These sub-agents decompose complex tasks and manage the LLM’s context length, especially during extended improvement cycles.
SICA 的架构包括用于基本文件操作、命令执行和算术计算的基础工具包。它包含结果提交机制和调用专门子智能体(编码、问题解决和推理)的功能。这些子智能体负责分解复杂任务并管理 LLM 的上下文长度,特别是在扩展改进周期期间。
An asynchronous overseer, another LLM, monitors SICA’s behavior, identifying potential issues such as loops or stagnation. It communicates with SICA and can intervene to halt execution if necessary. The overseer receives a detailed report of SICA’s actions, including a callgraph and a log of messages and tool actions, to identify patterns and inefficiencies.
一个异步监督者(另一个 LLM)监控 SICA 的行为,识别潜在问题,如循环或停滞。它与 SICA 进行通信,必要时可以介入以停止执行。监督者接收 SICA 行动的详细报告,包括调用图和消息及工具操作日志,以识别模式和低效率。
SICA’s LLM organizes information within its context window, its short-term memory, in a structured manner crucial to its operation. This structure includes a System Prompt defining agent goals, tool and sub-agent documentation, and system instructions. A Core Prompt contains the problem statement or instruction, content of open files, and a directory map. Assistant Messages record the agent’s step-by-step reasoning, tool and sub-agent call records and results, and overseer communications. This organization facilitates efficient information flow, enhancing LLM operation and reducing processing time and costs. Initially, file changes were recorded as diffs, showing only modifications and periodically consolidated.
SICA 的 LLM 在其上下文窗口(其短期记忆)中以对其操作至关重要的结构化方式组织信息。此结构包括定义智能体目标的系统提示词、工具和子智能体文档以及系统指令。核心提示词包含问题陈述或指令、打开文件的内容和目录映射。助手消息记录智能体的逐步推理、工具和子智能体调用记录及结果以及监督者通信。这种组织方式促进了高效的信息流动,增强了 LLM 操作并减少了处理时间和成本。最初,文件更改记录为差异,仅显示修改内容并定期合并。
SICA: A Look at the Code: Delving deeper into SICA’s implementation reveals several key design choices that underpin its capabilities. As discussed, the system is built with a modular architecture, incorporating several sub-agents, such as a coding agent, a problem-solver agent, and a reasoning agent. These sub-agents are invoked by the main agent, much like tool calls, serving to decompose complex tasks and efficiently manage context length, especially during those extended meta-improvement iterations.
SICA:代码深度解析: 深入研究 SICA 的实现揭示了支撑其能力的几个关键设计选择。如前所述,该系统采用模块化架构构建,包含多个子智能体,如编码智能体、问题解决智能体和推理智能体。这些子智能体由主智能体调用,类似于工具调用,用于分解复杂任务并有效管理上下文长度,特别是在这些扩展的元改进迭代期间。
The project is actively developed and aims to provide a robust framework for those interested in post-training LLMs on tool use and other agentic tasks, with the full code available for further exploration and contribution at the https://github.com/MaximeRobeyns/self_improving_coding_agent/ GitHub repository.
该项目正在积极开发中,旨在为对 LLM 工具使用及其他智能体任务进行后训练感兴趣的人提供一个强大框架,完整代码可在 GitHub 存储库 进一步探索和贡献。
For security, the project strongly emphasizes Docker containerization, meaning the agent runs within a dedicated Docker container. This is a crucial measure, as it provides isolation from the host machine, mitigating risks like inadvertent file system manipulation given the agent’s ability to execute shell commands.
出于安全考虑,该项目强烈强调 Docker 容器化,这意味着智能体在专用 Docker 容器内运行。这是一个关键措施,因为它提供了与主机的隔离,鉴于智能体执行 shell 命令的能力,这减轻了意外文件系统操作等风险。
To ensure transparency and control, the system features robust observability through an interactive webpage that visualizes events on the event bus and the agent’s callgraph. This offers comprehensive insights into the agent’s actions, allowing users to inspect individual events, read overseer messages, and collapse sub-agent traces for clearer understanding.
为确保透明度和控制,系统通过可视化事件总线上的事件和智能体调用图的交互式网页提供强大的可观察性。这提供了对智能体行动的全面洞察,允许用户检查单个事件、阅读监督者消息并折叠子智能体跟踪以获得更清晰的理解。
In terms of its core intelligence, the agent framework supports LLM integration from various providers, enabling experimentation with different models to find the best fit for specific tasks. Finally, a critical component is the asynchronous overseer, an LLM that runs concurrently with the main agent. This overseer periodically assesses the agent’s behavior for pathological deviations or stagnation and can intervene by sending notifications or even cancelling the agent’s execution if necessary. It receives a detailed textual representation of the system’s state, including a callgraph and an event stream of LLM messages, tool calls, and responses, which allows it to detect inefficient patterns or repeated work.
就其核心智能而言,智能体框架支持来自各种提供商的 LLM 集成,使用户能够尝试不同的模型以找到特定任务的最佳匹配。最后,一个关键组件是异步监督者,这是一个与主智能体并发运行的 LLM。此监督者定期评估智能体的行为是否存在病理性偏差或停滞,必要时可以通过发送通知甚至取消智能体的执行来介入。它接收系统状态的详细文本表示,包括调用图和 LLM 消息、工具调用和响应的事件流,这使它能够检测低效模式或重复工作。
A notable challenge in the initial SICA implementation was prompting the LLM-based agent to independently propose novel, innovative, feasible, and engaging modifications during each meta-improvement iteration. This limitation, particularly in fostering open-ended learning and authentic creativity in LLM agents, remains a key area of investigation in current research.
初始 SICA 实现中的一个显著挑战是提示基于 LLM 的智能体在每次元改进迭代期间独立提出新颖、创新、可行且引人入胜的修改。这一限制,特别是在培养 LLM 智能体的开放式学习和真正创造力方面,仍然是当前研究的关键领域。
AlphaEvolve and OpenEvolve
AlphaEvolve 和 OpenEvolve
AlphaEvolve is an AI agent developed by Google designed to discover and optimize algorithms. It utilizes a combination of LLMs, specifically Gemini models (Flash and Pro), automated evaluation systems, and an evolutionary algorithm framework. This system aims to advance both theoretical mathematics and practical computing applications.
AlphaEvolve 是 Google 开发的一个 AI 智能体,旨在发现和优化算法。它利用 LLM 的组合,特别是 Gemini 模型(Flash 和 Pro)、自动化评估系统和进化算法框架。该系统旨在推动理论数学和实际计算应用的发展。
AlphaEvolve employs an ensemble of Gemini models. Flash is used for generating a wide range of initial algorithm proposals, while Pro provides more in-depth analysis and refinement. Proposed algorithms are then automatically evaluated and scored based on predefined criteria. This evaluation provides feedback that is used to iteratively improve the solutions, leading to optimized and novel algorithms.
AlphaEvolve 采用 Gemini 模型的集合。Flash 用于生成广泛的初始算法提案,而 Pro 提供更深入的分析和改进。然后根据预定义标准自动评估和评分提出的算法。此评估提供用于迭代改进解决方案的反馈,从而产生优化和新颖的算法。
In practical computing, AlphaEvolve has been deployed within Google’s infrastructure. It has demonstrated improvements in data center scheduling, resulting in a 0.7% reduction in global compute resource usage. It has also contributed to hardware design by suggesting optimizations for Verilog code in upcoming Tensor Processing Units (TPUs). Furthermore, AlphaEvolve has accelerated AI performance, including a 23% speed improvement in a core kernel of the Gemini architecture and up to 32.5% optimization of low-level GPU instructions for FlashAttention.
在实际计算中,AlphaEvolve 已部署在 Google 的基础设施中。它在数据中心调度方面展示了改进,导致全球计算资源使用减少 0.7%。它还通过为即将推出的张量处理单元(TPU)的 Verilog 代码提出优化建议来促进硬件设计。此外,AlphaEvolve 加速了 AI 性能,包括 Gemini 架构核心内核的 23% 速度提升以及 FlashAttention 的低级 GPU 指令的最高 32.5% 优化。
In the realm of fundamental research, AlphaEvolve has contributed to the discovery of new algorithms for matrix multiplication, including a method for 4x4 complex-valued matrices that uses 48 scalar multiplications, surpassing previously known solutions. In broader mathematical research, it has rediscovered existing state-of-the-art solutions to over 50 open problems in 75% of cases and improved upon existing solutions in 20% of cases, with examples including advancements in the kissing number problem.
在基础研究领域,AlphaEvolve 为矩阵乘法新算法的发现做出了贡献,包括使用 48 次标量乘法的 4x4 复数值矩阵方法,超过了先前已知的解决方案。在更广泛的数学研究中,它在 75% 的情况下重新发现了超过 50 个开放问题的现有最先进解决方案,并在 20% 的情况下改进了现有解决方案,例子包括接吻数问题的进步。
OpenEvolve is an evolutionary coding agent that leverages LLMs (see Fig.3) to iteratively optimize code. It orchestrates a pipeline of LLM-driven code generation, evaluation, and selection to continuously enhance programs for a wide range of tasks. A key aspect of OpenEvolve is its capability to evolve entire code files, rather than being limited to single functions. The agent is designed for versatility, offering support for multiple programming languages and compatibility with OpenAI-compatible APIs for any LLM. Furthermore, it incorporates multi-objective optimization, allows for flexible prompt engineering, and is capable of distributed evaluation to efficiently handle complex coding challenges.
Fig. 3: The OpenEvolve internal architecture is managed by a controller. This controller orchestrates several key components: the program sampler, Program Database, Evaluator Pool, and LLM Ensembles. Its primary function is to facilitate their learning and adaptation processes to enhance code quality.
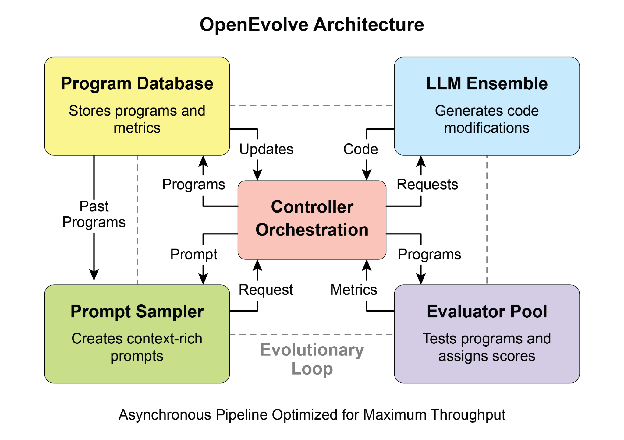
OpenEvolve 是一个利用大语言模型(见图3)迭代优化代码的进化编码智能体。它编排 LLM 驱动的代码生成、评估和选择流水线,持续为广泛任务增强程序。OpenEvolve 的一个关键方面是它能够进化完整代码文件,而不仅限于单个函数。该智能体设计为多功能,支持多种编程语言,并与任何 LLM 的 OpenAI 兼容 API 兼容。此外,它整合了多目标优化,允许灵活的提示工程,并能够进行分布式评估以高效处理复杂的编码挑战。
图 3:OpenEvolve 内部架构由控制器管理。该控制器编排几个关键组件:程序采样器、程序数据库、评估器池和 LLM 集合。其主要功能是促进它们的学习和适应过程以提高代码质量。
This code snippet uses the OpenEvolve library to perform evolutionary optimization on a program. It initializes the OpenEvolve system with paths to an initial program, an evaluation file, and a configuration file. The evolve.run(iterations=1000) line starts the evolutionary process, running for 1000 iterations to find an improved version of the program. Finally, it prints the metrics of the best program found during the evolution, formatted to four decimal places.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
from openevolve import OpenEvolve
## Initialize the system
evolve = OpenEvolve(
initial_program_path="path/to/initial_program.py",
evaluation_file="path/to/evaluator.py",
config_path="path/to/config.yaml"
)
## Run the evolution
best_program = await evolve.run(iterations=1000)
print(f"Best program metrics:")
for name, value in best_program.metrics.items():
print(f" {name}: {value:.4f}")
此代码片段使用 OpenEvolve 库对程序执行进化优化。它使用初始程序、评估文件和配置文件的路径初始化 OpenEvolve 系统。evolve.run(iterations=1000) 行启动进化过程,运行 1000 次迭代以找到程序的改进版本。最后,它打印在进化过程中找到的最佳程序的指标,格式化为四位小数。
At a Glance
速览
What: AI agents often operate in dynamic and unpredictable environments where pre-programmed logic is insufficient. Their performance can degrade when faced with novel situations not anticipated during their initial design. Without the ability to learn from experience, agents cannot optimize their strategies or personalize their interactions over time. This rigidity limits their effectiveness and prevents them from achieving true autonomy in complex, real-world scenarios.
问题背景: AI 智能体通常在动态且不可预测的环境中运行,在这些环境中预编程逻辑是不够的。当面对初始设计期间未预料到的新情况时,它们的性能可能会下降。没有从经验中学习的能力,智能体无法随时间优化其策略或个性化其交互。这种刚性限制了它们的有效性,并阻止它们在复杂的现实世界场景中实现真正的自主性。
Why: The standardized solution is to integrate learning and adaptation mechanisms, transforming static agents into dynamic, evolving systems. This allows an agent to autonomously refine its knowledge and behaviors based on new data and interactions. Agentic systems can use various methods, from reinforcement learning to more advanced techniques like self-modification, as seen in the Self-Improving Coding Agent (SICA). Advanced systems like Google’s AlphaEvolve leverage LLMs and evolutionary algorithms to discover entirely new and more efficient solutions to complex problems. By continuously learning, agents can master new tasks, enhance their performance, and adapt to changing conditions without requiring constant manual reprogramming.
解决方案: 标准化解决方案是集成学习和适应机制,将静态智能体转变为动态的、演化的系统。这使智能体能够基于新数据和交互自主改进其知识和行为。智能体系统可以使用各种方法,从强化学习到更高级的技术,如自我改进编码智能体(SICA)中所见的自我修改。像 Google 的 AlphaEvolve 这样的高级系统利用 LLM 和进化算法来发现全新的、更高效的复杂问题解决方案。通过持续学习,智能体可以掌握新任务、增强其性能并适应变化的条件,而无需持续的手动重新编程。
Rule of thumb: Use this pattern when building agents that must operate in dynamic, uncertain, or evolving environments. It is essential for applications requiring personalization, continuous performance improvement, and the ability to handle novel situations autonomously.
实践建议: 在构建必须在动态、不确定或演化环境中运行的智能体时使用此模式。它对于需要个性化、持续性能改进以及自主处理新情况的能力的应用至关重要。
Visual summary
Fig.4: Learning and adapting pattern
可视化摘要
图 4:学习和适应模式
Key Takeaways
关键要点
- Learning and Adaptation are about agents getting better at what they do and handling new situations by using their experiences.
- “Adaptation” is the visible change in an agent’s behavior or knowledge that comes from learning.
- SICA, the Self-Improving Coding Agent, self-improves by modifying its code based on past performance. This led to tools like the Smart Editor and AST Symbol Locator.
- Having specialized “sub-agents” and an “overseer” helps these self-improving systems manage big tasks and stay on track.
- The way an LLM’s “context window” is set up (with system prompts, core prompts, and assistant messages) is super important for how efficiently agents work.
- This pattern is vital for agents that need to operate in environments that are always changing, uncertain, or require a personal touch.
- Building agents that learn often means hooking them up with machine learning tools and managing how data flows.
- An agent system, equipped with basic coding tools, can autonomously edit itself, and thereby improve its performance on benchmark tasks
-
AlphaEvolve is Google’s AI agent that leverages LLMs and an evolutionary framework to autonomously discover and optimize algorithms, significantly enhancing both fundamental research and practical computing applications.
- 学习和适应是智能体通过经验改进自身行为并处理新情况的过程
- “适应”是学习导致的智能体行为或知识的可见变化
- 自我改进编码智能体(SICA)通过基于过去表现修改代码进行自我改进,产生了智能编辑器、AST 符号定位器等工具
- 拥有专门的”子智能体”和”监督者”有助于这些自我改进系统管理大型任务并保持正轨
- LLM 上下文窗口的设置方式(使用系统提示词、核心提示词和助手消息)对智能体的工作效率至关重要
- 此模式对于需要在不断变化、不确定或需要个性化的环境中运行的智能体至关重要
- 构建学习型智能体通常意味着将它们与机器学习工具连接起来并管理数据流动方式
- 配备基本编码工具的智能体系统可以自主编辑自身,从而提高其在基准任务上的性能
- AlphaEvolve 是 Google 的 AI 智能体,利用 LLM 和进化框架自主发现和优化算法,显著增强基础研究和实际计算应用
Conclusion
结论
This chapter examines the crucial roles of learning and adaptation in Artificial Intelligence. AI agents enhance their performance through continuous data acquisition and experience. The Self-Improving Coding Agent (SICA) exemplifies this by autonomously improving its capabilities through code modifications.
本章探讨了学习和适应在人工智能中的关键作用。AI 智能体通过持续的数据获取和经验来增强其性能。自我改进编码智能体(SICA)通过代码修改自主改进其能力,很好地例证了这一点。
We have reviewed the fundamental components of agentic AI, including architecture, applications, planning, multi-agent collaboration, memory management, and learning and adaptation. Learning principles are particularly vital for coordinated improvement in multi-agent systems. To achieve this, tuning data must accurately reflect the complete interaction trajectory, capturing the individual inputs and outputs of each participating agent.
我们已经回顾了智能体 AI 的基本组成部分,包括架构、应用、规划、多智能体协作、记忆管理以及学习和适应。学习原理对于多智能体系统的协调改进特别重要。要实现这一点,调优数据必须准确反映完整的交互轨迹,捕获每个参与智能体的输入和输出。
These elements contribute to significant advancements, such as Google’s AlphaEvolve. This AI system independently discovers and refines algorithms by LLMs, automated assessment, and an evolutionary approach, driving progress in scientific research and computational techniques. Such patterns can be combined to construct sophisticated AI systems. Developments like AlphaEvolve demonstrate that autonomous algorithmic discovery and optimization by AI agents are attainable.
这些元素促成了重大进展,如 Google 的 AlphaEvolve。这个 AI 系统通过 LLM、自动化评估和进化方法独立发现和改进算法,推动科学研究和计算技术的进步。这些模式可以组合起来构建复杂的 AI 系统。像 AlphaEvolve 这样的发展表明,AI 智能体自主算法发现和优化是可以实现的。
References
参考文献
- Sutton, R. S., & Barto, A. G. (2018). Reinforcement Learning: An Introduction. MIT Press
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press
- Mitchell, T. M. (1997). Machine Learning. McGraw-Hill
- Proximal Policy Optimization Algorithms by John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. You can find it on arXiv: https://arxiv.org/abs/1707.06347
- Robeyns, M., Aitchison, L., & Szummer, M. (2025). A Self-Improving Coding Agent. arXiv:2504.15228v2. https://arxiv.org/pdf/2504.15228 https://github.com/MaximeRobeyns/self_improving_coding_agent
- AlphaEvolve blog, https://deepmind.google/discover/blog/alphaevolve-a-gemini-powered-coding-agent-for-designing-advanced-algorithms/
- OpenEvolve, https://github.com/codelion/openevolve